

TL;DR: In this post, you will learn how to choose the best node for your Kubernetes cluster before writing any code.
When you create a Kubernetes cluster, one of the first questions you may have is: “What type of worker nodes should I use, and how many of them?”
Or if you’re using a managed Kubernetes service like Linode Kubernetes Engine (LKE), should you use eight Linode 2 GB or two Linode 8 GB instances to achieve your desired computing capacity?
First, not all resources in worker nodes can be used to run workloads.
Kubernetes Node Reservations
In a Kubernetes node, CPU and memory are divided into:
- Operating system
- Kubelet, CNI, CRI, CSI (and system daemons)
- Pods
- Eviction threshold
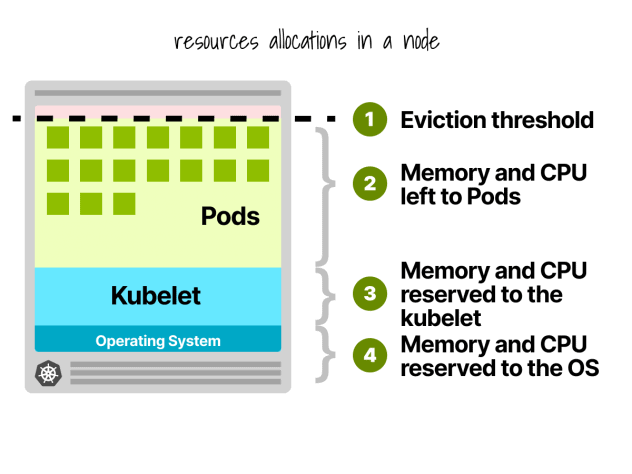
Let’s give a quick example.
Imagine you have a cluster with a single Linode 2GB compute instance, or 1 vCPU and 2GB of RAM.
The following resources are reserved for the kubelet and operating system:
- -500MB of memory.
- -60m of CPU.
On top of that, 100MB is reserved for the eviction threshold.
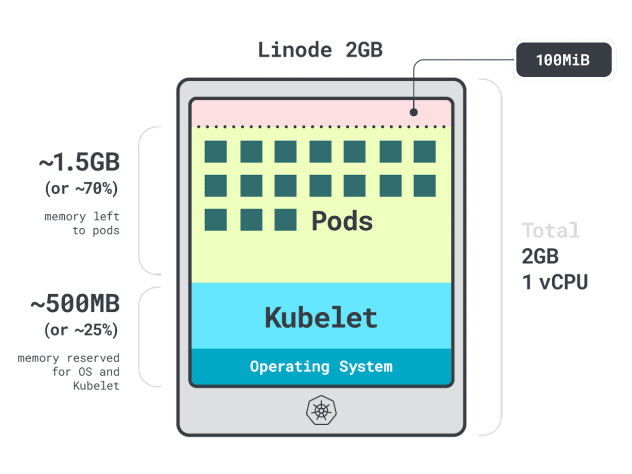
In total, that’s 30% of memory and 6% of CPU that you can’t use.
Every cloud provider has its way of defining limits, but for the CPU, they seem to all agree on the following values:
- 6% of the first core;
- 1% of the next core (up to 2 cores);
- 0.5% of the next 2 cores (up to 4); and
- 0.25% of any cores above four cores.
As for the memory limits, this varies a lot between providers.
But in general, the reservation follows this table:
- 25% of the first 4 GB of memory;
- 20% of the following 4 GB of memory (up to 8 GB);
- 10% of the following 8 GB of memory (up to 16 GB);
- 6% of the next 112 GB of memory (up to 128 GB); and
- 2% of any memory above 128 GB.
Now that you know how resources are reparted inside a worker node, it’s time to ask the tricky question: which instance should you choose?
Since there could be many correct answers, let’s restrict our options by focusing on the best worker node for your workload.
Profiling Apps
In Kubernetes, you have two ways to specify how much memory and CPU a container can use:
- Requests usually match the app consumption at normal operations.
- Limits set the maximum number of resources allowed.
The Kubernetes scheduler uses requests to determine where the pod should be allocated in the cluster. Since the scheduler doesn’t know the consumption (the pod hasn’t started yet), it needs a hint. Those “hints” are requests; you can have one for the memory and one for the CPU.
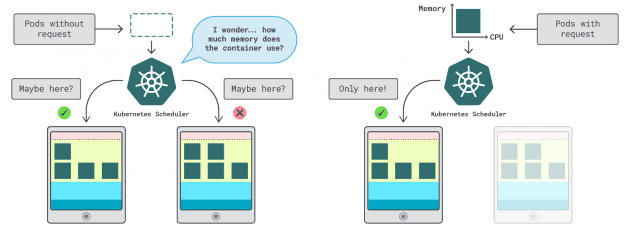
The kubelet uses limits to stop the process when it uses more memory than is allowed. It also throttles the process if it uses more CPU time than allowed.
But how do you choose the right values for requests and limits?
You can measure your workload performance (i.e. average, 95th and 99th percentile, etc.) and use those as requests as limits. To ease the process, two convenient tools can speed up the analysis:
The VPA collects the memory and CPU utilization data and runs a regression algorithm that suggests requests and limits for your deployment. It is an official Kubernetes project and can also be instrumented to adjust the values automatically– you can have the controller update the requests and limits directly in your YAML.
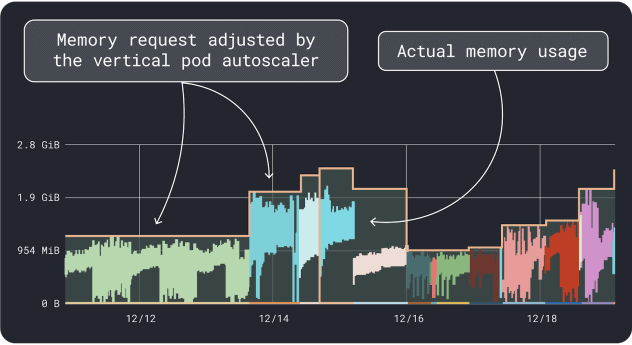
KRR works similarly, but it leverages the data you export via Prometheus. As the first step, your workloads should be instrumented to export metrics to Prometheus. Once you store all the metrics, you can use KRR to analyze the data and suggest requests and limits.
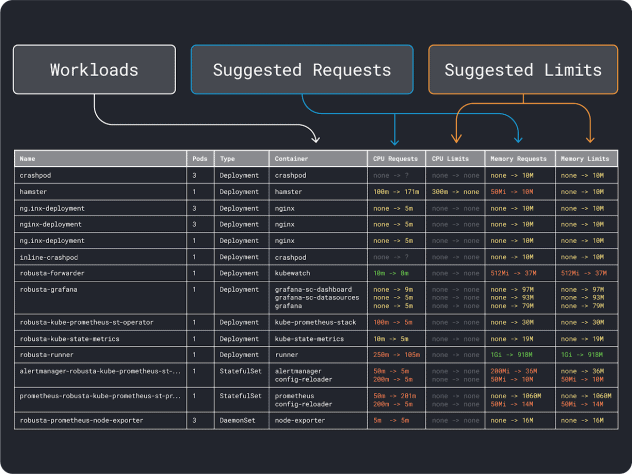
Once you have an idea of the (rough) resource requirements, you can finally move on to select an instance type.
Selecting an Instance Type
Imagine you estimated your workload requires 2GB of memory requests, and you estimate needing at least ~10 replicas.
You can already rule out most small instances with less than `2GB * 10 = 20GB`. At this point, you can guess an instance that could work well: let’s pick Linode 32GB.
Next, you can divide memory and CPU by the maximum number of pods that can be deployed on that instance (i.e. 110 in LKE) to obtain a discrete unit of memory and CPU.
For example, the CPU and memory units for the Linode 32 GB are:
- 257MB for the memory unit (i.e. (32GB – 3.66GB reserved) / 110)
- 71m for the CPU unit (i.e. (8000m – 90m reserved) / 110)
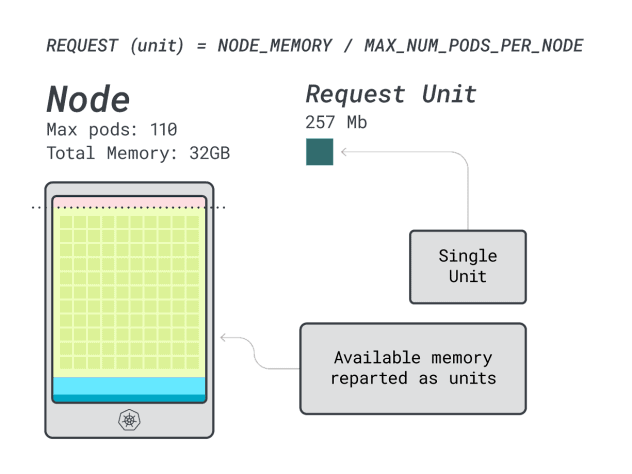
Excellent! In the last (and final) step, you can use those units to estimate how many workloads can fit the node.
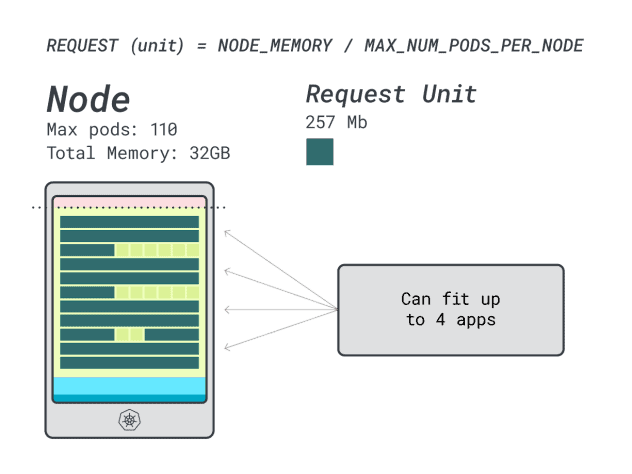
Assuming you want to deploy a Spring Boot with requests of 6GB and 1 vCPU, this translates to:
- The smallest number of units that fits 6GB is 24 unit (24 * 257MB = 6.1GB)
- The smallest number of units that fits 1 vCPU is 15 units (15 * 71m = 1065m)
The numbers suggest that you will run out of memory before you run out of CPU, and you can have at most (110/24) 4 apps deployed in the cluster.
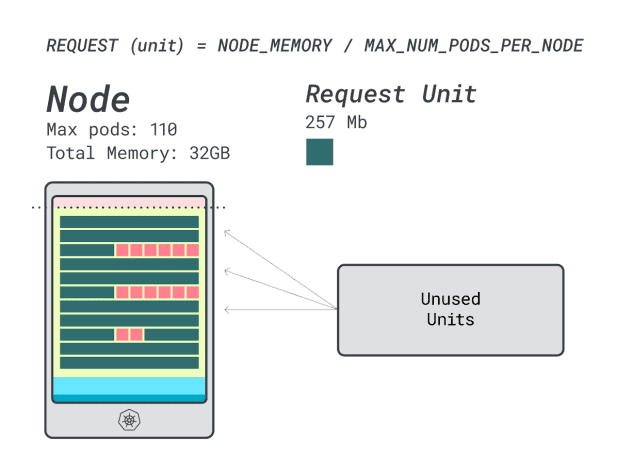
When you run four workloads on this instance, you use:
- 24 memory units \* 4 = 96 units and 14 are left unused (~12%)
- 15 vCPU units \* 4 = 60 units and 50 are left unused (~45%)
Not bad, but can we do better?
Let’s try with a Linode 64 GB instance (64GB / 16 vCPU).
Assuming you want to deploy the same app, the numbers change to:
- A memory unit is ~527MB (i.e. (64GB – 6.06GB reserved) / 110).
- A CPU unit is ~145m (i.e. (16000m – 110m reserved) / 110).
- The smallest number of units that fits 6GB is 12 unit (12 * 527MB = 6.3GB).
- The smallest number of units that fits 1 vCPU is 7 units (7 * 145m = 1015m).
How many workloads can you fit in this instance?
Since you will max out the memory and each workload requires 12 units, the max number of apps is 9 (i.e. 110/12)
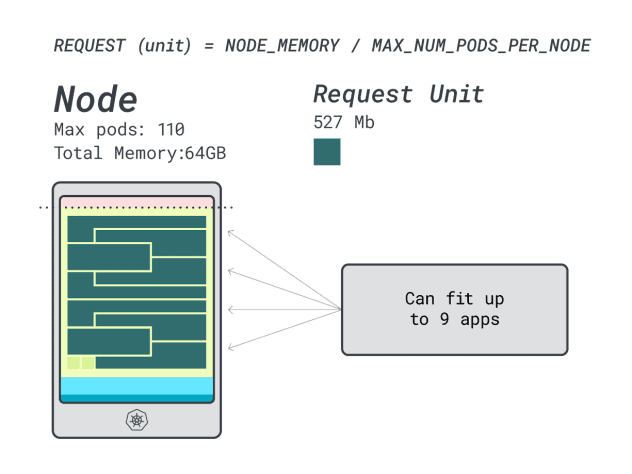
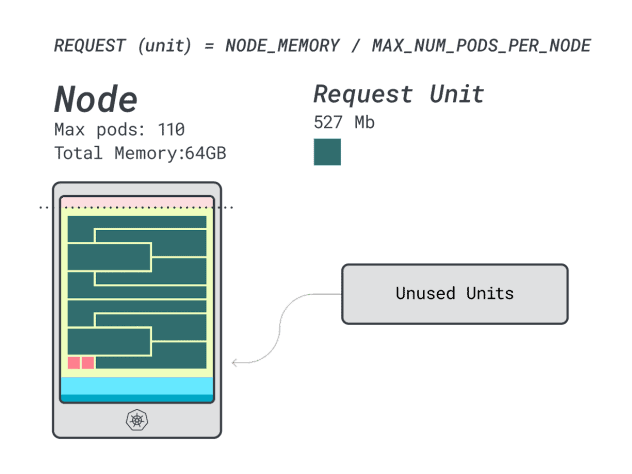
If you compute the efficiency/wastage, you will find:
- 12 memory units \* 9 = 108 units and 2 are left unused (~2%)
- 7 vCPU units \* 9 = 63 units and 47 are left unused (~42%)
While the numbers for the wasted CPU are almost identical to the previous instance, the memory utilization is drastically improved.
We can finally compare costs:
- The Linode 32 GB instance can fit at most 4 workloads. At total capacity, each pod costs $48 / month (i.e. $192 cost of the instance divided by four workloads.)
- *The Linode 64 GB instance can fit up to 9 workloads. At total capacity, each pod costs $42.6 / month (i.e. $384 cost of the instance divided by nine workloads).
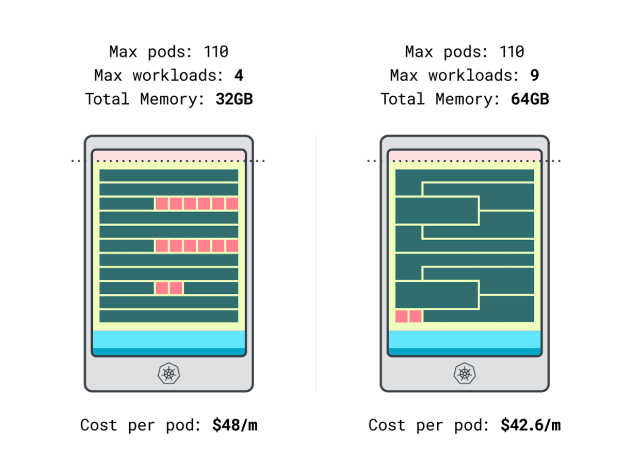
In other words, choosing the larger instance size can save you up to $6 per month per workload. Great!
Comparing Nodes Using the Calculator
But what if you want to test more instances? Making those calculations is a lot of work.
Speed up the process using the learnk8s calculator.
The first step in using the calculator is to enter your memory and CPU requests. The system automatically computes reserved resources and suggests utilization and costs. There are some additional helpful features: assign CPU and memory requests close to the application usage. If the application occasionally bursts into higher CPU or memory usage, that’s fine.
But what happens when all Pods use all resources to their limits?
This could lead to overcommitment. The widget in the center gives you a percentage of CPU or memory overcommitment.
What happens when you overcommit?
- If you overcommit on memory, the kubelet will evict pods and move them elsewhere in the cluster.
- If you overcommit on the CPU, the workloads will use the available CPU proportionally.
Finally, you can use the DaemonSets and Agent widget, a convenient mechanism to model pods that run on all your nodes. For example, LKE has the Cilium and CSI plugin deployed as DaemonSets. Those pods use resources that aren’t available to your workloads and should be subtracted from the calculations. The widget lets you do just that!
Summary
In this article, you dived into a systematic process to price and identify worker nodes for your LKE cluster.
You learned how Kubernetes reserves resources for nodes and how you can optimise your cluster to take advantage of it. Want to learn more? Register to see this in action with our webinar in partnership with Akamai cloud computing services.



Comments