

简要说明:在本文章中,您将了解如何在编写任何代码之前为 Kubernetes 集群选择最佳节点。
当你创建 Kubernetes 集群时,你可能会遇到的第一个问题是:"我应该使用哪种类型的工作节点?"我应该使用哪种类型的工作节点?
或者,如果您使用的是 Linode Kubernetes Engine (LKE) 这样的 Kubernetes 托管服务,您应该使用 8 个 Linode 2 GB 还是 2 个 Linode 8 GB 实例来实现所需的计算能力?
首先,并非工作节点中的所有资源都能用于运行工作负载。
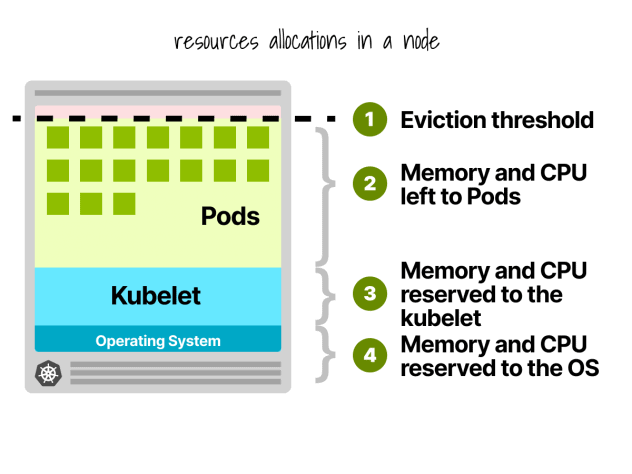
Kubernetes 节点预订
在 Kubernetes 节点中,CPU 和内存被划分为
- 操作系统
- Kubelet、CNI、CRI、CSI(和系统守护进程)
- 豆荚
- 驱逐门槛
让我们举一个简单的例子。
想象一下,您有一个集群,其中有一个Linode 2GB 计算实例,或 1 个 vCPU 和 2GB 内存。
为 kubelet 和操作系统保留了以下资源:
- -500MB 内存。
- 中央处理器 -60 米。
此外,还为驱逐阈值预留了 100MB 的空间。
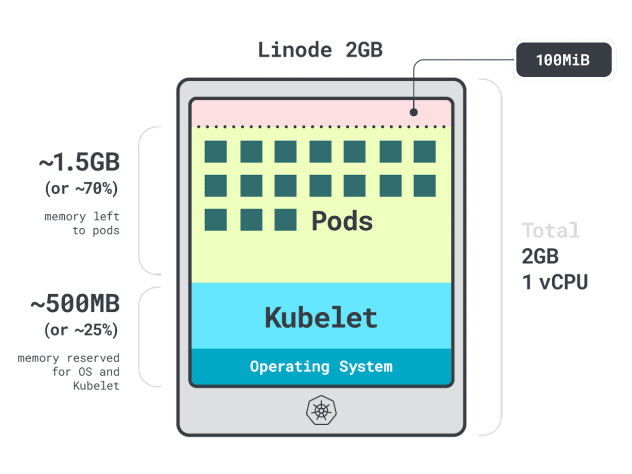
总共有30%的内存和6%的 CPU 无法使用。
每个云提供商都有自己定义限制的方式,但对于 CPU 而言,他们似乎都同意以下值:
- 占第一个核心的 6%;
- 下一个内核的 1%(最多 2 个内核);
- 下两个核心(最多 4 个)的 0.5%;以及
- 四个以上核心的 0.25%。
至于内存限制,不同提供商之间有很大差异。
但总的来说,保留是按照这个表格进行的:
- 前 4 GB 内存的 25%;
- 以下内存的 20% 4 GB(最多 8 GB);
- 以下内容的 10% 8 GB 内存(最多 16 GB);
- 下一个 112 GB 内存的 6%(最多 128 GB);以及
- 128 GB 以上内存的 2%。
既然知道了工作节点内的资源是如何重新分配的,那么就该问一个棘手的问题了:应该选择哪个实例?
由于正确答案可能有很多,因此我们将重点放在最适合您工作负载的工作节点上,以限制我们的选择范围。
剖析应用程序
在 Kubernetes 中,有两种方法可以指定容器可以使用多少内存和 CPU:
- 请求 通常与应用程序正常运行时的消耗量相匹配。
- 限制 设置了允许的最大资源数量。
Kubernetes 调度器使用请求来确定 pod 在集群中的分配位置。由于调度程序不知道消耗量(pod 尚未启动),因此需要一个提示。这些 "提示 "就是请求;你可以有一个用于内存,一个用于 CPU。
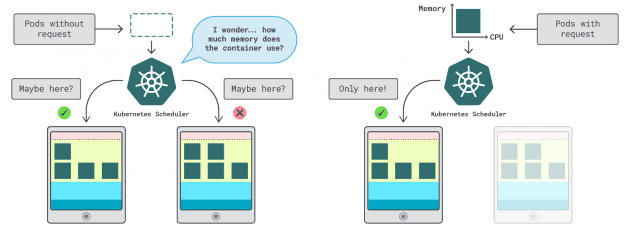
当进程使用的内存超过允许值时,kubelet 会使用限制来停止进程。如果进程占用的 CPU 时间超过允许值,它还会对进程进行节流。
但是,如何为请求和限制选择正确的值呢?
您可以测量您的工作负载性能(即平均值、第 95 和 99 百分位数等),并将其作为限制请求。为了简化这一过程,有两个方便的工具可以加快分析速度:
VPA 会收集内存和 CPU 利用率数据,并运行一种回归算法,为你的部署提出请求和限制。它是 Kubernetes 的官方项目,也可以通过仪器自动调整值--你可以让控制器直接在 YAML 中更新请求和限制。
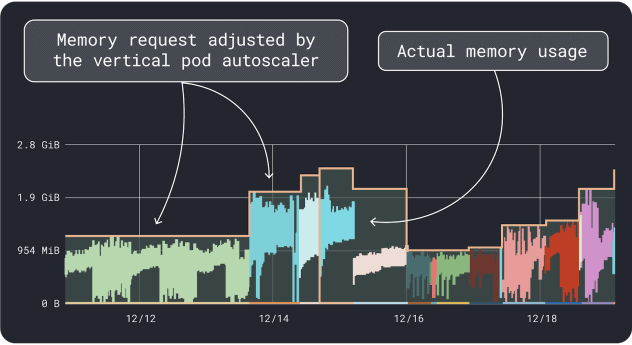
KRR 的工作原理类似,但它利用您通过 Prometheus.第一步,应该对工作负载进行检测,以便将指标导出到Prometheus 。存储所有指标后,就可以使用 KRR 分析数据并提出请求和限制。
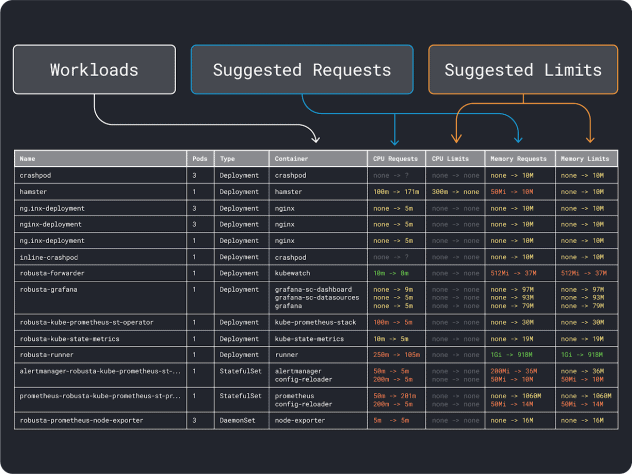
了解了(大致的)资源需求后,最后就可以选择实例类型了。
选择实例类型
假设您估计您的工作负载需要 2GB 的内存请求,并且您估计至少需要 ~10 个副本。
您已经可以排除大多数小于 "2GB * 10 = 20GB "的小型实例。此时,您可以猜测一个可以很好运行的实例:让我们选择 Linode 32GB。
然后,将内存和 CPU 除以该实例上可部署的最大 pod 数量(即 LKE 中的 110),即可得到一个离散的内存和 CPU 单位。
例如,Linode 32 GB 的 CPU 和内存单元为
- 内存单元 257MB(即(32GB - 3.66GB 保留)/110)
- 中央处理器单元 71 米(即(8000 米-预留 90 米)/110)
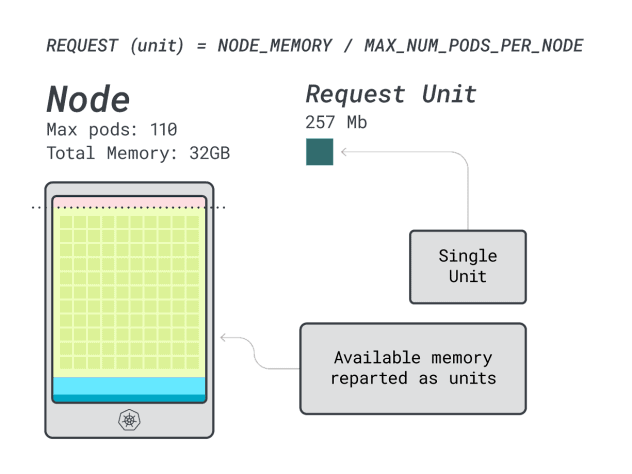
非常好在最后一步(也是最后一步),您可以使用这些单位来估算节点可以容纳多少工作负载。
假设您要部署一个请求为 6GB 和 1 个 vCPU 的 Spring Boot,这就意味着
- 适合 6GB 的最小单元数是 24 单元(24 * 257MB = 6.1GB)
- 适合 1 个 vCPU 的最小单元数为 15 个单元(15 * 71m = 1065m)
这些数字表明,在 CPU 用完之前,内存就会用完,而群集中最多只能部署 (110/24) 4 个应用程序。
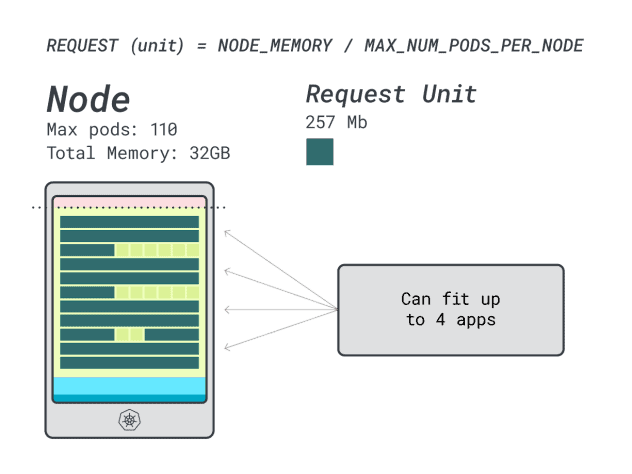
当您在该实例上运行四个工作负载时,您可以使用
- 24 个内存单元 \* 4 = 96 个单元,还有 14 个单元未使用(~12%)。
- 15 个 vCPU 单元 \* 4 = 60 个单元,50 个单元未使用(~45%)。
不错,但我们能做得更好吗?
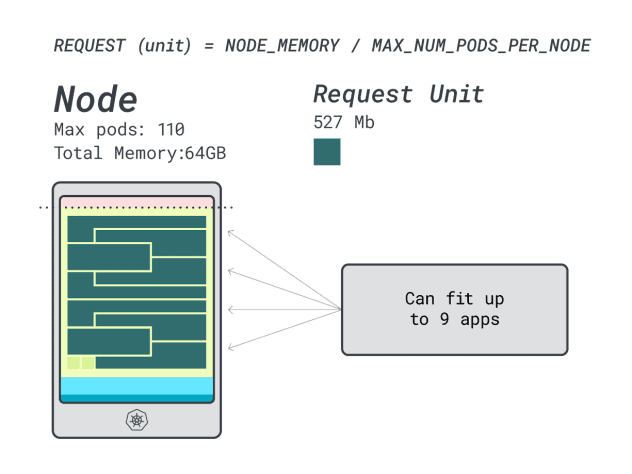
让我们用 Linode 64 GB 实例(64GB/16 vCPU)来试试。
假设您要部署相同的应用程序,数字将变为
- 一个内存单位约为 527MB(即(64GB - 6.06GB 保留)/110)。
- 一个 CPU 单元约为 145 米(即(16000 米-预留 110 米)/110)。
- 适合 6GB 的最小单位数是 12 单位(12 * 527MB = 6.3GB)。
- 适合 1 个 vCPU 的最小单元数为 7 个单元(7 * 145m = 1015m)。
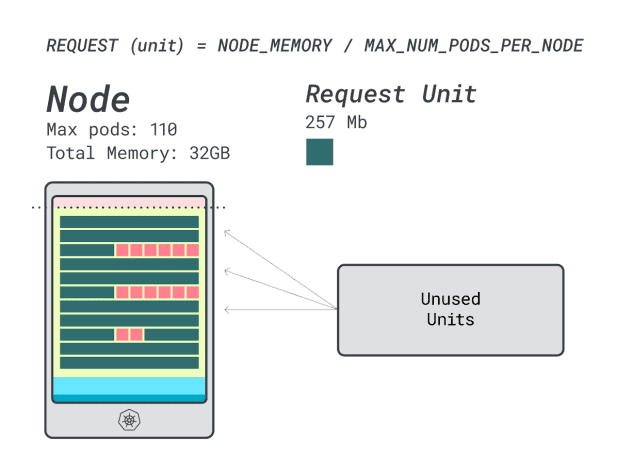
这个实例可以容纳多少工作负载?
由于内存将达到最大值,而每个工作负载需要 12 个单元,因此应用程序的最大数量为 9 个(即 110/12)。
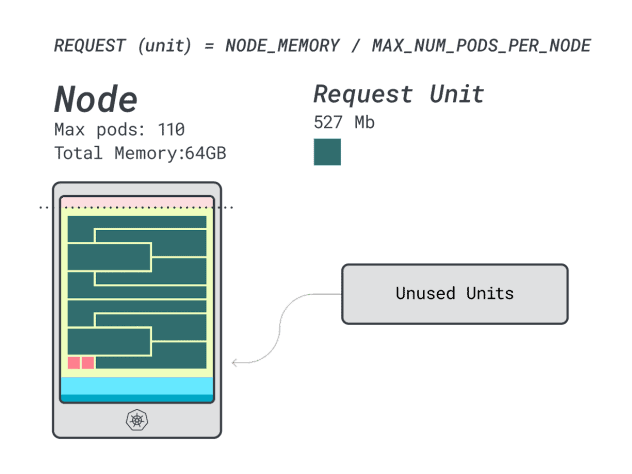
如果计算一下效率/损耗,你会发现
- 12 个内存单元 \* 9 = 108 个单元,2 个单元未使用(~2%)。
- 7 个 vCPU 单元 \* 9 = 63 个单元,还有 47 个单元未使用(~42%)。
虽然浪费 CPU 的数据与之前的实例几乎相同,但内存利用率却大幅提高。
我们终于可以比较成本了:
- Linode 32 GB 实例最多可容纳 4 个工作负载。按总容量计算,每个 pod 的成本为 48 美元/月(即 192 美元的实例成本除以 4 个工作负载)。
- *Linode 64 GB 实例最多可容纳 9 个工作负载。按总容量计算,每个 pod 的成本为 42.6 美元/月(即 384 美元的实例成本除以 9 个工作负载)。
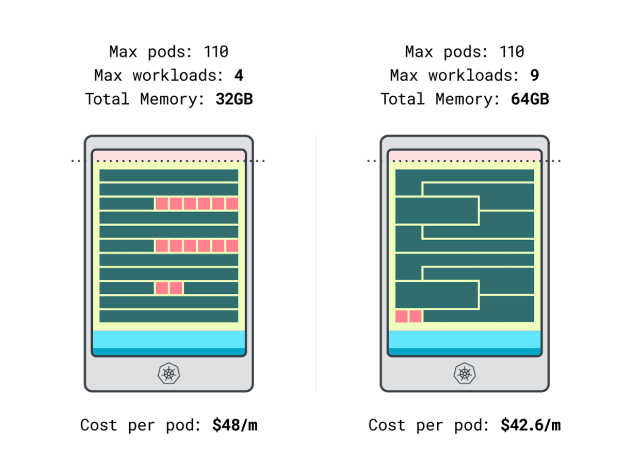
换句话说,选择较大的实例大小,每个工作量每月最多可节省 6 美元。好极了!
使用计算器比较节点
但如果要测试更多实例怎么办?进行这些计算需要大量的工作。
使用learnk8s计算器加快进程。
使用计算器的第一步是输入您的内存和 CPU 请求。系统会自动计算预留资源,并建议使用率和成本。还有一些其他有用的功能:根据应用程序的使用情况分配 CPU 和内存请求。如果应用程序偶尔会突然出现较高的 CPU 或内存使用率,也没关系。
但是,如果所有的 "花苞 "都把资源用到了极限,会发生什么呢?
这可能会导致超量使用。中间的小部件会显示 CPU 或内存超量占用的百分比。
过度承诺会发生什么?
- 如果超量使用内存,kubelet 会驱逐 pod 并将其转移到集群中的其他地方。
- 如果超量使用 CPU,工作负载将按比例使用可用的 CPU。
最后,您可以使用 DaemonSets 和 Agent widget,这是一种方便的机制,可以为在所有节点上运行的 pod 建模。例如,LKE 将 Cilium 和 CSI 插件部署为 DaemonSets。这些 pod 使用的资源不能用于工作负载,因此应从计算中减去。这个小工具可以让你做到这一点!
摘要
在本文中,您将深入了解为 LKE 集群定价和确定工作节点的系统过程。
您了解了 Kubernetes 如何为节点储备资源,以及如何优化集群以利用这些资源。还想了解更多?注册参加我们与Akamai云计算服务公司合作举办的网络研讨会,了解Kubernetes的实际应用。




注释