

TL;DR: この投稿では、コードを書く前にKubernetesクラスタに最適なノードを選択する方法を学びます。
Kubernetesクラスタを作成する際、最初に抱く疑問の1つがある:「どんなワーカーノードをいくつ使えばいいのか?
あるいは、Linode Kubernetes Engine (LKE)のようなマネージドKubernetesサービスを使用している場合、希望のコンピューティング容量を達成するために、8台のLinode 2GBインスタンスと2台のLinode 8GBインスタンスのどちらを使用すべきでしょうか?
まず、ワーカーノードのすべてのリソースをワークロードの実行に使用できるわけではない。
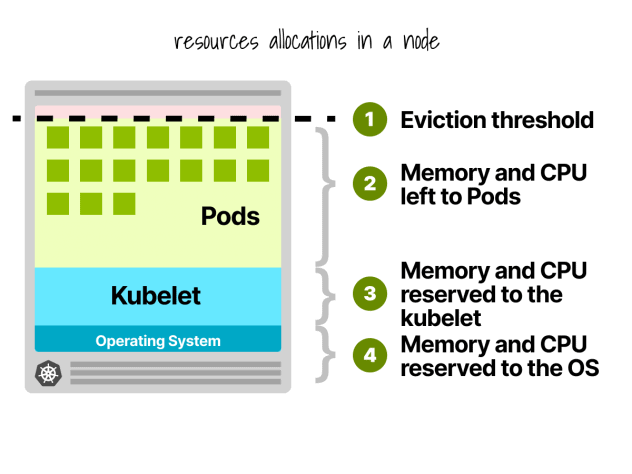
Kubernetesノードの予約
Kubernetesノードでは、CPUとメモリが分割されている:
- オペレーティングシステム
- Kubelet、CNI、CRI、CSI(およびシステム・デーモン)
- ポッド
- 立ち退きの閾値
簡単な例を挙げよう。
単一のLinode 2GBコンピュートインスタンス、または1つのvCPUと2GBのRAMを持つクラスタがあるとします。
以下のリソースは、kubeletとオペレーティング・システム用に予約されています:
- -500MBのメモリー。
- CPUの-60m。
その上、100MBが退去のしきい値として確保されている。
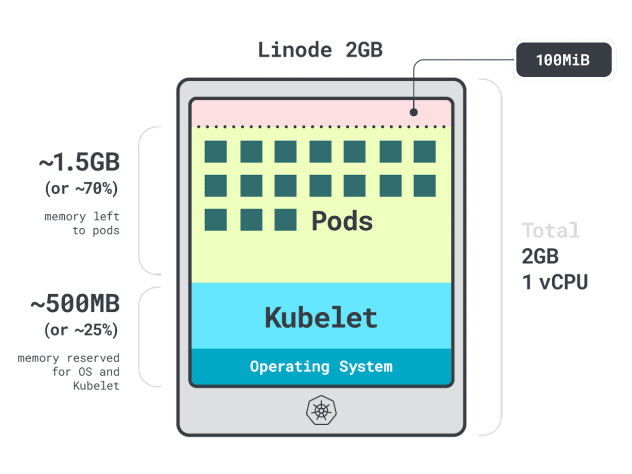
合計すると、メモリの30%、CPUの6%が使えないことになる。
各クラウド・プロバイダーはそれぞれ制限値を定めているが、CPUに関しては以下の値で一致しているようだ:
- 最初のコアの6%;
- 次のコアの1%(最大2コア);
- 次の2コアの0.5%(最大4コア)。
- 4コア以上のコアの0.25%。
メモリの制限に関しては、プロバイダーによって大きく異なる。
しかし、一般的に予約はこの表に従っている:
- 最初の4GBのメモリの25%;
- 以下の20% 4GBのメモリ(最大8GB);
- 以下の10% メモリ8GB(最大16GB);
- 次の112GBのメモリの6%(最大128GB)。
- 128GB以上のメモリの2%。
さて、ワーカーノード内でリソースがどのように再配置されるかがわかったところで、いよいよ厄介な質問だ。どのインスタンスを選ぶべきか?
正解はいくつもあるはずなので、ワークロードに最適なワーカーノードに絞って、選択肢を絞り込んでみましょう。
アプリのプロファイリング
Kubernetesでは、コンテナが使用できるメモリとCPUの量を指定する2つの方法がある:
- リクエストは 通常運用時のアプリ消費量と一致する。
- 制限は 、許可されるリソースの最大数を設定する。
Kubernetesのスケジューラはリクエストを使用して、クラスタ内のどこにPodを割り当てるべきかを決定します。スケジューラーは消費量を知らないので(ポッドはまだ起動していない)、ヒントが必要だ。この "ヒント "がリクエストで、メモリ用とCPU用があります。
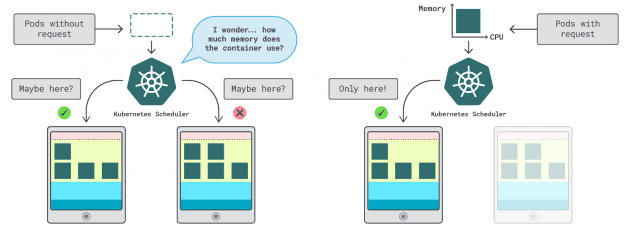
kubeletは、許容以上のメモリを使用した場合、制限を使用してプロセスを停止します。また、許容以上のCPU時間を使用した場合、プロセスをスロットルします。
しかし、要求と制限の正しい値をどのように選べばいいのだろうか?
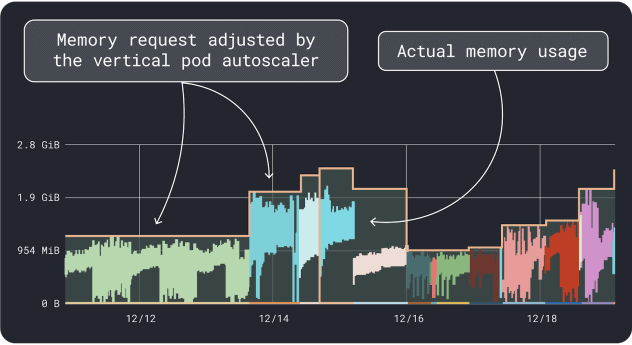
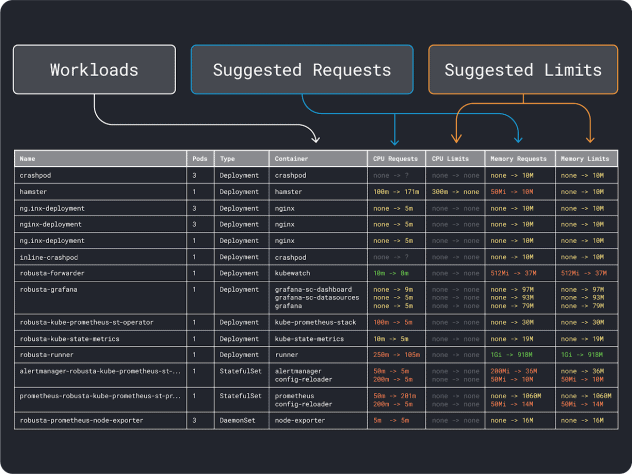
ワークロードのパフォーマンス(平均、95パーセンタイル、99パーセンタイルなど)を測定し、それを限界値としてリクエストに使用することができる。このプロセスを簡単にするために、2つの便利なツールが分析をスピードアップします:
VPAはメモリとCPUの使用率データを収集し、デプロイのリクエストと制限を提案するリグレッションアルゴリズムを実行します。これは公式のKubernetesプロジェクトであり、値を自動的に調整するためにインスツルメンテーションすることもできます。
KRRも同様ですが、以下の方法でエクスポートしたデータを活用します。 Prometheus.最初のステップとして、ワークロードは Prometheus にメトリクスをエクスポートするようにインスツルメンテーションする必要があります。全てのメトリクスを保存したら、KRRを使ってデータを分析し、要求と制限を提案することができます。
大まかな)リソース要件を把握したら、いよいよインスタンスタイプの選択に移る。
インスタンスタイプの選択
ワークロードに2GBのメモリ要求が必要で、少なくとも~10個のレプリカが必要だと見積もったとしよう。
2GB * 10 = 20GB`未満の小さなインスタンスはすでに除外できます。この時点で、うまくいきそうなインスタンスを推測できます:Linodeの32GBを選んでみましょう。
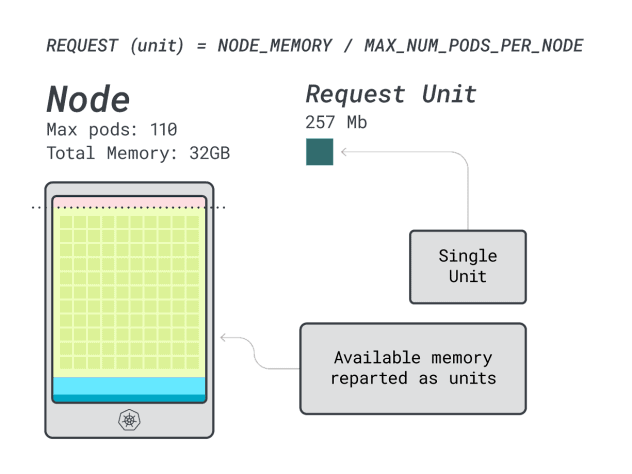
次に、メモリとCPUを、そのインスタンスにデプロイできるポッドの最大数(LKEでは110)で割って、メモリとCPUの個別単位を得ることができます。
例えば、Linode 32GBのCPUとメモリユニットは以下の通りです:
- メモリーユニット257MB(つまり(32GB-3.66GB予約)÷110)
- CPUユニット71m(つまり(8000m-90m予約)÷110)
素晴らしい!最後の(そして最後の)ステップでは、これらの単位を使って、ノードに適合するワークロードの数を見積もることができる。
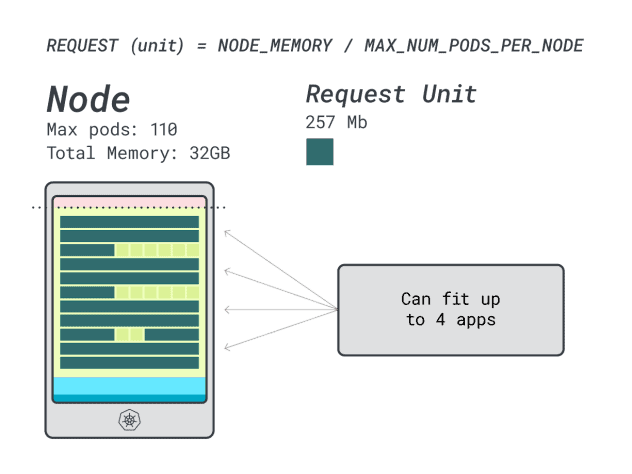
6GBのリクエストと1つのvCPUでSpring Bootをデプロイすると仮定すると、次のようになる:
- 6GBに収まる最小のユニット数は24ユニット(24 * 257MB = 6.1GB)です。
- 1vCPUに収まる最小のユニット数は15ユニット(15 * 71m = 1065m)。
この数字は、CPUが足りなくなる前にメモリが足りなくなることを示唆しており、クラスタには最大でも(110/24)4つのアプリをデプロイできる。
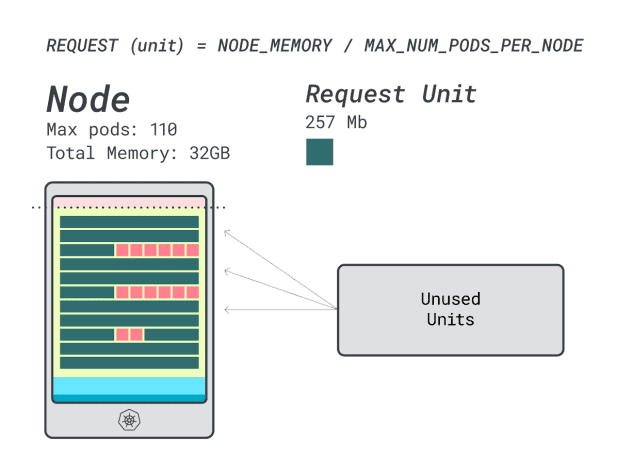
このインスタンスで4つのワークロードを実行する場合、次のようにする:
- 24 メモリユニット \* 4 = 96 ユニットで、14 ユニットが未使用(~12%)。
- vCPU 15台 ╱* 4 = 60台で、50台が未使用(~45%)
悪くはない。
Linodeの64GBインスタンス(64GB / 16 vCPU)で試してみましょう。
同じアプリをデプロイすると仮定すると、数字は次のように変わる:
- メモリ単位は~527MB(つまり(64GB-6.06GB予約)/110)。
- CPUユニットは~145m(つまり(16000m-110m予約)÷110)。
- 6GBに収まる最小のユニット数は12ユニット(12 * 527MB = 6.3GB)。
- 1vCPUに収まる最小のユニット数は7ユニット(7 * 145m = 1015m)。
このインスタンスにいくつのワークロードを入れられるか?
メモリは最大で、各ワークロードは12ユニットを必要とするので、アプリの最大数は9(つまり110/12)。
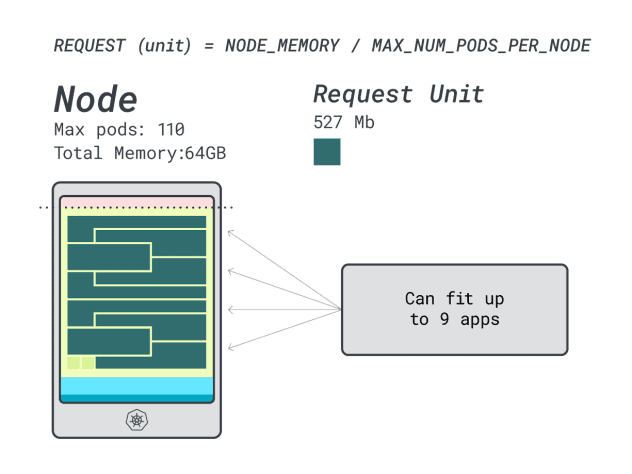
効率と無駄を計算すると、こうなる:
- 12 メモリユニット \* 9 = 108 ユニットで、2ユニット未使用(~2%)。
- 7 vCPUユニット ╱* 9 = 63ユニットで、47ユニットが未使用(~42%)
無駄なCPUの数値は前のインスタンスとほぼ同じだが、メモリの使用率は劇的に改善されている。
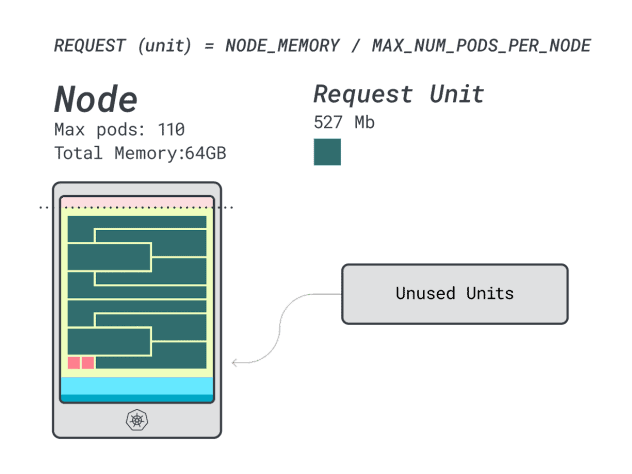
ようやくコスト比較ができる:
- Linodeの32GBインスタンスは、最大4つのワークロードに対応できます。合計容量では、各ポッドのコストは48ドル/月です(つまり、インスタンスのコスト192ドルを4つのワークロードで割ったものです)。
- *Linodeの64GBインスタンスは最大9つのワークロードに対応します。合計容量では、各ポッドのコストは42.6ドル/月です(つまり、インスタンスのコスト384ドルを9つのワークロードで割ったもの)。
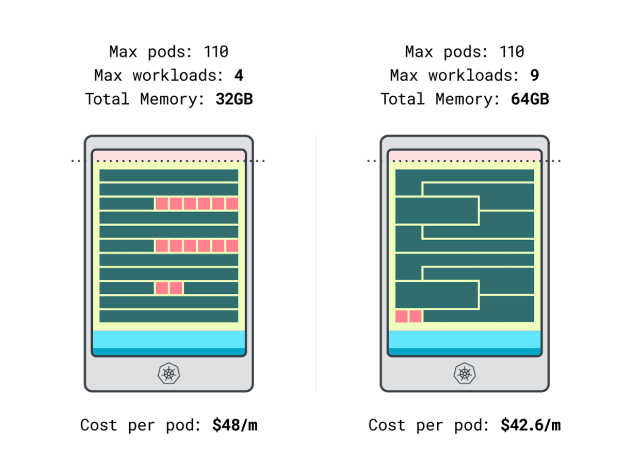
言い換えれば、より大きなインスタンスサイズを選択することで、ワークロードあたり月額最大6ドルの節約になる。素晴らしい!
電卓を使ったノードの比較
しかし、もっと多くのインスタンスをテストしたい場合はどうする?そのような計算をするのは大変な作業だ。
learnk8s電卓を使用してプロセスをスピードアップ。
計算機を使用する最初のステップは、メモリとCPUの要求を入力することです。システムは自動的に予約リソースを計算し、使用率とコストを提案します。さらに便利な機能があります:アプリケーションの使用状況に近いCPUとメモリの要求を割り当てます。アプリケーションが時折、CPUやメモリの使用率が高くなることがあっても、それは問題ありません。
しかし、すべてのポッドがすべてのリソースを限界まで使ったらどうなるのか?
これはオーバーコミットにつながる可能性がある。中央のウィジェットは、CPUやメモリのオーバーコミットのパーセンテージを表示します。
オーバーコミットするとどうなるか?
- メモリをオーバーコミットすると、kubeletはポッドを退去させ、クラスター内の別の場所に移動させる。
- CPUをオーバーコミットした場合、ワークロードは利用可能なCPUを比例して使用する。
最後に、DaemonSets と Agent ウィジェットを使用して、すべてのノードで実行されるポッドをモデル化する便利なメカニズムを使用できます。たとえば、LKEにはCiliumとCSIプラグインがDaemonSetsとしてデプロイされています。これらのポッドは、ワークロードが利用できないリソースを使用するため、計算から差し引く必要があります。ウィジェットを使用すると、それを実行できます!
まとめ
この記事では、LKEクラスタ用のワーカーノードの価格設定と識別のための体系的なプロセスを紹介しました。
Kubernetesがどのようにノードにリソースをリザーブするのか、そしてそれを活用するためにクラスタをどのように最適化できるのかを学びました。もっと詳しく知りたいですか?アカマイのクラウド・コンピューティング・サービスとのパートナーシップによるウェビナーにご登録の上、実際にご覧ください。



コメント