


TL;DR: Neste post, você aprenderá como escolher o melhor nó para seu cluster Kubernetes antes de escrever qualquer código.
Quando cria um cluster Kubernetes, uma das primeiras perguntas que pode ter é: "Que tipo de nós de trabalho devo usar e quantos deles?"
Ou, se estiver a utilizar um serviço Kubernetes gerido como o Linode Kubernetes Engine (LKE), deve utilizar oito instâncias Linode de 2 GB ou duas instâncias Linode de 8 GB para atingir a capacidade de computação pretendida?
Primeiro, nem todos os recursos nos nós de trabalho podem ser usados para executar cargas de trabalho.
Reservas de nós do Kubernetes
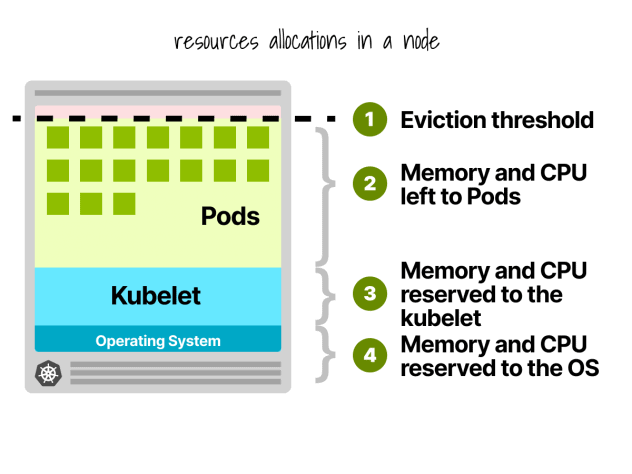
Em um nó Kubernetes, a CPU e a memória são divididas em:
- Sistema operativo
- Kubelet, CNI, CRI, CSI (e daemons do sistema)
- Cápsulas
- Limiar de despejo
Vamos dar um exemplo rápido.
Imagine que tem um cluster com uma única instância de computação Linode 2GB, ou 1 vCPU e 2GB de RAM.
Os seguintes recursos estão reservados para o kubelet e o sistema operativo:
- -500 MB de memória.
- -60m de CPU.
Para além disso, 100MB estão reservados para o limiar de despejo.
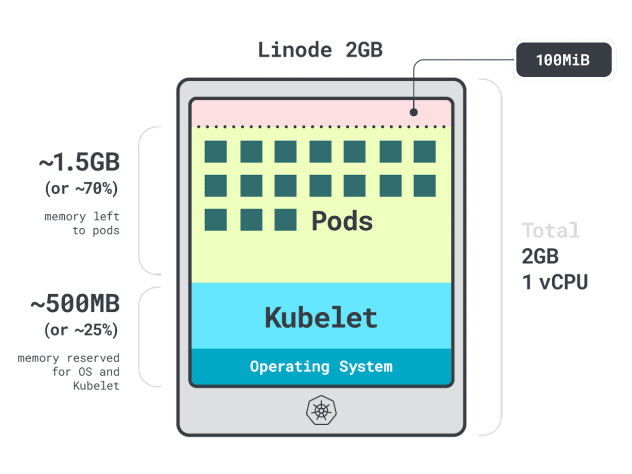
No total, são 30% da memória e 6% da CPU que não pode utilizar.
Cada fornecedor de serviços de nuvem tem a sua forma de definir os limites, mas para a CPU, todos parecem concordar com os seguintes valores:
- 6% do primeiro núcleo;
- 1% do núcleo seguinte (até 2 núcleos);
- 0,5% dos 2 núcleos seguintes (até 4); e
- 0,25% de todos os núcleos acima de quatro núcleos.
Quanto aos limites de memória, estes variam muito consoante os fornecedores.
Mas, em geral, a reserva segue este quadro:
- 25% dos primeiros 4 GB de memória;
- 20% dos seguintes 4 GB de memória (até 8 GB);
- 10% dos seguintes 8 GB de memória (até 16 GB);
- 6% dos 112 GB de memória seguintes (até 128 GB); e
- 2% de qualquer memória superior a 128 GB.
Agora que sabe como os recursos são repartidos dentro de um nó de trabalho, está na altura de fazer a pergunta complicada: que instância deve escolher?
Como pode haver muitas respostas correctas, vamos restringir as nossas opções, concentrando-nos no melhor nó de trabalho para a sua carga de trabalho.
Aplicações de definição de perfis
No Kubernetes, existem duas formas de especificar a quantidade de memória e CPU que um contentor pode utilizar:
- Os pedidos correspondem normalmente ao consumo da aplicação em operações normais.
- Os limites definem o número máximo de recursos permitidos.
O agendador do Kubernetes usa solicitações para determinar onde o pod deve ser alocado no cluster. Como o agendador não sabe o consumo (o pod ainda não foi iniciado), ele precisa de uma dica. Essas "dicas" são solicitações; você pode ter uma para a memória e outra para a CPU.
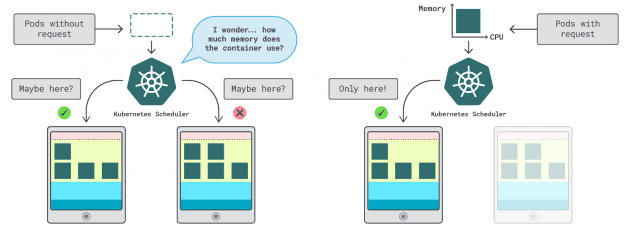
O kubelet usa limites para parar o processo quando ele usa mais memória do que o permitido. Ele também limita o processo se ele usar mais tempo de CPU do que o permitido.
Mas como é que se escolhem os valores correctos para os pedidos e os limites?
Pode medir o desempenho da sua carga de trabalho (ou seja, média, percentil 95 e 99, etc.) e utilizá-los como pedidos e limites. Para facilitar o processo, duas ferramentas convenientes podem acelerar a análise:
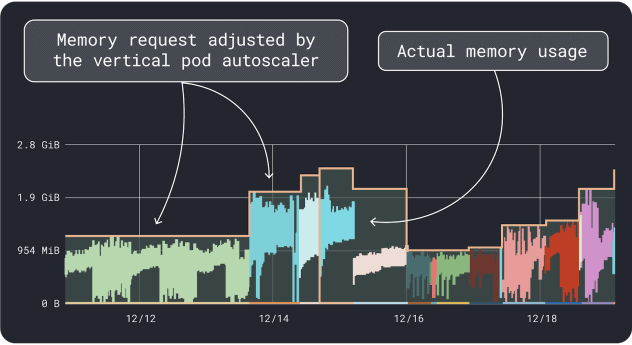
O VPA coleta os dados de utilização de memória e CPU e executa um algoritmo de regressão que sugere solicitações e limites para sua implantação. É um projeto oficial do Kubernetes e também pode ser instrumentado para ajustar os valores automaticamente -você pode fazer com que o controlador atualize as solicitações e os limites diretamente no seu YAML.
O KRR funciona de forma semelhante, mas aproveita os dados que exporta através do Prometheus. Como primeira etapa, suas cargas de trabalho devem ser instrumentadas para exportar métricas para Prometheus. Depois de armazenar todas as métricas, você pode usar o KRR para analisar os dados e sugerir solicitações e limites.
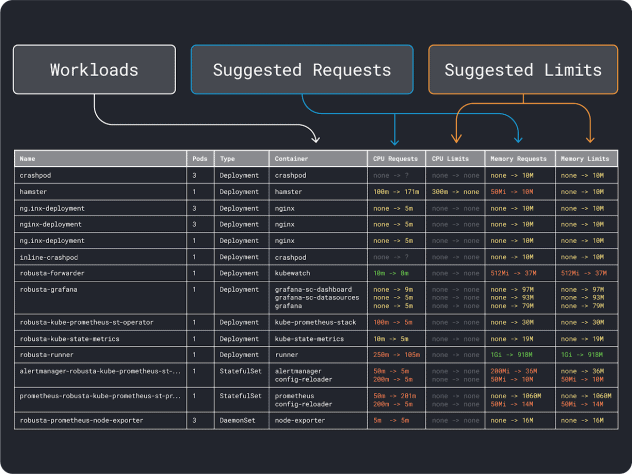
Quando tiver uma ideia dos requisitos (aproximados) de recursos, pode finalmente selecionar um tipo de instância.
Selecionar um tipo de instância
Imagine que estima que a sua carga de trabalho requer 2 GB de pedidos de memória e que estima precisar de pelo menos ~10 réplicas.
Já é possível descartar a maioria das instâncias pequenas com menos de `2GB * 10 = 20GB`. Neste ponto, pode adivinhar uma instância que poderia funcionar bem: vamos escolher Linode 32GB.
Em seguida, você pode dividir a memória e a CPU pelo número máximo de pods que podem ser implantados nessa instância (ou seja, 110 em LKE) para obter uma unidade discreta de memória e CPU.
Por exemplo, as unidades de CPU e memória para o Linode 32 GB são:
- 257MB para a unidade de memória (ou seja, (32GB - 3,66GB reservados) / 110)
- 71m para a unidade CPU (ou seja, (8000m - 90m reservados) / 110)
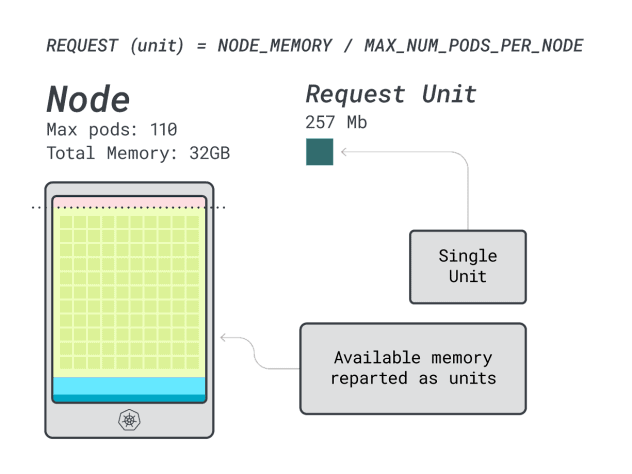
Excelente! No último (e último) passo, pode utilizar essas unidades para estimar quantas cargas de trabalho podem caber no nó.
Supondo que pretende implementar um Spring Boot com pedidos de 6GB e 1 vCPU, isto traduz-se em:
- O número mais pequeno de unidades que cabem em 6GB é 24 unidades (24 * 257MB = 6,1GB)
- O menor número de unidades que cabe em 1 vCPU é 15 unidades (15 * 71m = 1065m)
Os números sugerem que ficará sem memória antes de ficar sem CPU, e que pode ter no máximo (110/24) 4 aplicações implementadas no cluster.
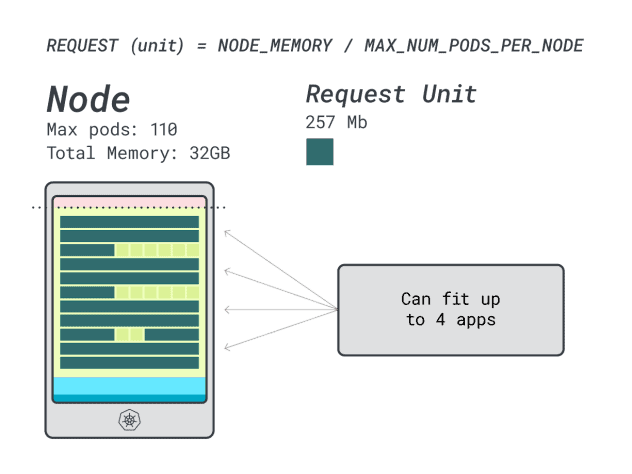
Quando você executa quatro cargas de trabalho nesta instância, você usa:
- 24 unidades de memória \* 4 = 96 unidades e 14 não são utilizadas (~12%)
- 15 unidades vCPU \* 4 = 60 unidades e 50 não são utilizadas (~45%)
Não é mau, mas será que podemos fazer melhor?
Vamos tentar com uma instância Linode 64 GB (64GB / 16 vCPU).
Partindo do princípio de que pretende implementar a mesma aplicação, os números mudam para:
- Uma unidade de memória tem ~527MB (ou seja, (64GB - 6,06GB reservados) / 110).
- Uma unidade de CPU tem ~145m (ou seja, (16000m - 110m reservados) / 110).
- O menor número de unidades que cabe em 6GB é 12 unidades (12 * 527MB = 6,3GB).
- O menor número de unidades que cabe em 1 vCPU é 7 unidades (7 * 145m = 1015m).
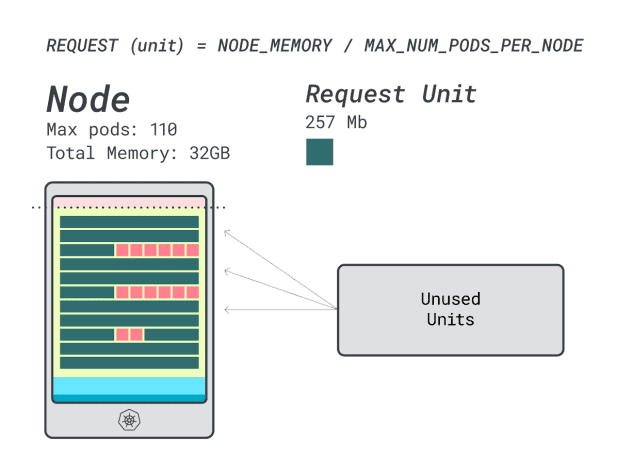
Quantas cargas de trabalho podem caber nesta instância?
Uma vez que vai esgotar a memória e cada carga de trabalho requer 12 unidades, o número máximo de aplicações é 9 (ou seja, 110/12)
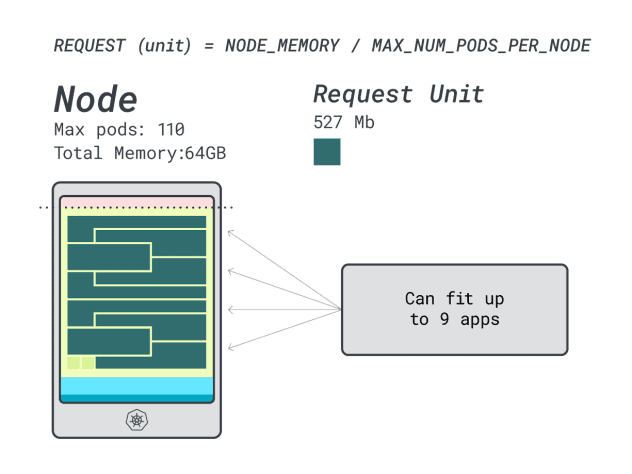
Se calcular a eficiência/desperdício, obterá:
- 12 unidades de memória \* 9 = 108 unidades e 2 não são utilizadas (~2%)
- 7 unidades vCPU \* 9 = 63 unidades e 47 não são utilizadas (~42%)
Embora os números da CPU desperdiçada sejam quase idênticos aos da instância anterior, a utilização da memória melhorou drasticamente.
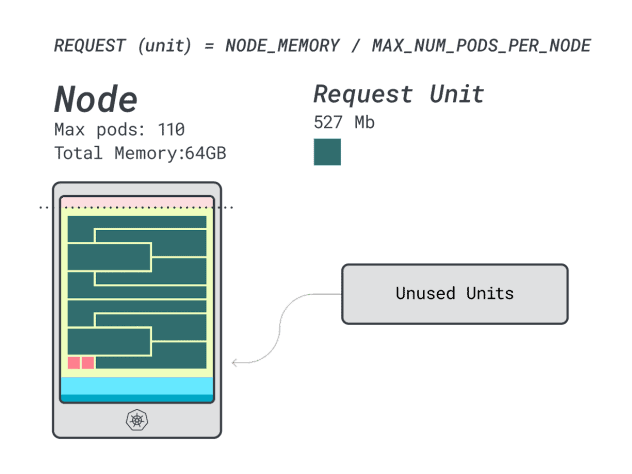
Podemos finalmente comparar os custos:
- A instância Linode de 32 GB pode acomodar no máximo 4 cargas de trabalho. Na capacidade total, cada pod custa $48 / mês (ou seja, $192 de custo da instância dividido por quatro cargas de trabalho).
- *A instância Linode de 64 GB pode acomodar até 9 cargas de trabalho. Na capacidade total, cada pod custa $42,6 / mês (ou seja, $384 de custo da instância dividido por nove cargas de trabalho).
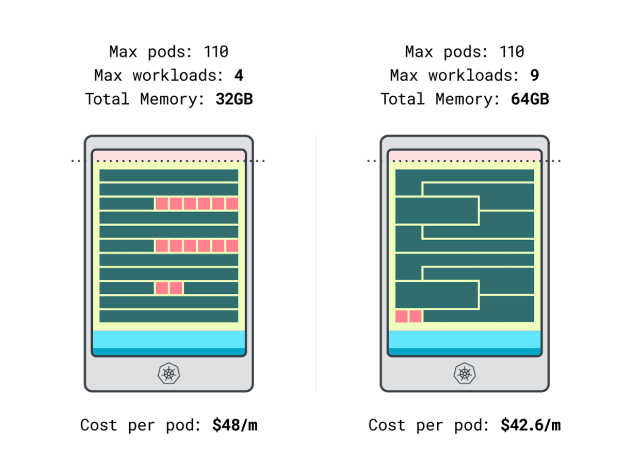
Por outras palavras, escolher o tamanho de instância maior pode poupar até $6 por mês por carga de trabalho. Ótimo!
Comparação de nós usando a calculadora
Mas e se quiser testar mais instâncias? Fazer esses cálculos dá muito trabalho.
Acelere o processo utilizando a calculadora learnk8s.
O primeiro passo para utilizar a calculadora é introduzir os seus pedidos de memória e CPU. O sistema calcula automaticamente os recursos reservados e sugere a utilização e os custos. Existem algumas funcionalidades adicionais úteis: atribuir pedidos de CPU e memória próximos da utilização da aplicação. Se a aplicação ocasionalmente atingir uma utilização mais elevada da CPU ou da memória, não há problema.
Mas o que acontece quando todos os Pods utilizam todos os recursos até ao limite?
Isso pode levar a um excesso de comprometimento. O widget no centro dá-lhe uma percentagem de excesso de ocupação da CPU ou da memória.
O que acontece quando nos comprometemos demasiado?
- Se o compromisso com a memória for excessivo, o kubelet irá expulsar os pods e movê-los para outro local no cluster.
- Se o comprometimento da CPU for excessivo, as cargas de trabalho usarão a CPU disponível proporcionalmente.
Finalmente, pode usar o widget DaemonSets e Agent, um mecanismo conveniente para modelar pods que correm em todos os seus nós. Por exemplo, o LKE tem o plug-in Cilium e CSI implantado como DaemonSets. Esses pods usam recursos que não estão disponíveis para as suas cargas de trabalho e devem ser subtraídos dos cálculos. O widget permite-lhe fazer isso mesmo!
Resumo
Neste artigo, mergulhou num processo sistemático para determinar o preço e identificar nós de trabalho para o seu cluster LKE.
Aprendeu como o Kubernetes reserva recursos para nós e como pode otimizar o seu cluster para tirar partido disso. Quer saber mais? Registe-se para ver isto em ação com o nosso webinar em parceria com os serviços de computação em nuvem da Akamai.




Comentários