


요약: 이 포스팅에서는 코드를 작성하기 전에 Kubernetes 클러스터에 가장 적합한 노드를 선택하는 방법을 알아보세요.
Kubernetes 클러스터를 생성할 때 가장 먼저 갖게 되는 질문 중 하나는 다음과 같습니다: "어떤 유형의 워커 노드를 사용해야 하며, 몇 개를 사용해야 하는가?"입니다.
또는 Linode Kubernetes Engine(LKE)과 같은 관리형 Kubernetes 서비스를 사용하는 경우, 원하는 컴퓨팅 용량을 달성하기 위해 8개의 Linode 2GB 또는 2개의 Linode 8GB 인스턴스를 사용해야 할까요?
첫째, 워커 노드의 모든 리소스를 워크로드 실행에 사용할 수 있는 것은 아닙니다.
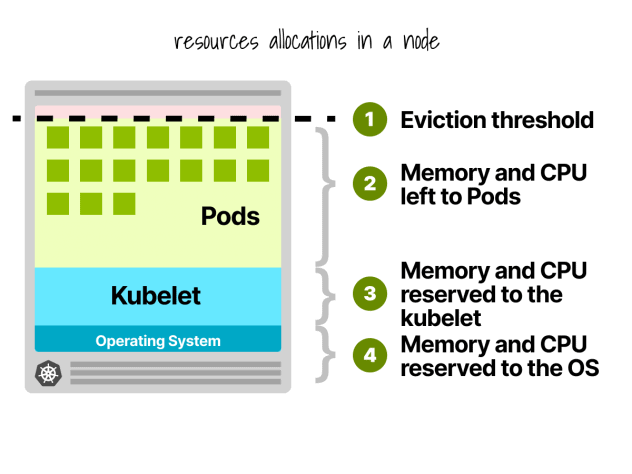
쿠버네티스 노드 예약
쿠버네티스 노드에서 CPU와 메모리는 다음과 같이 나뉩니다:
- 운영 체제
- Kubelet, CNI, CRI, CSI(및 시스템 데몬)
- 포드
- 퇴거 임계값
간단한 예를 들어 보겠습니다.
단일 리노드 2GB 컴퓨팅 인스턴스 또는 1개의 vCPU와 2GB RAM이 있는 클러스터가 있다고 가정해 보겠습니다.
다음 리소스는 kubelet 및 운영 체제용으로 예약되어 있습니다:
- -500MB의 메모리.
- CPU -60m.
또한 퇴거 임계값으로 100MB가 예약되어 있습니다.
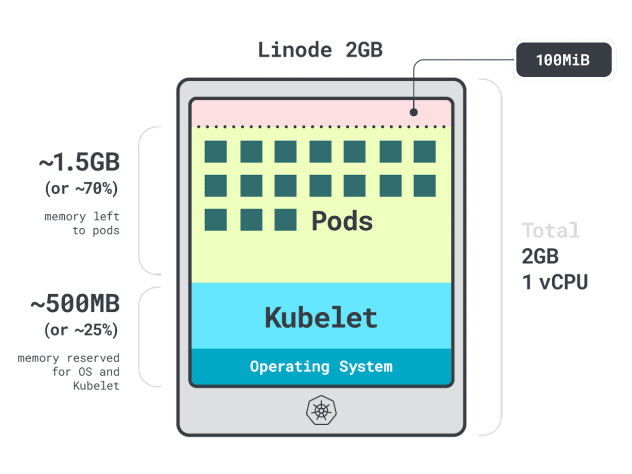
총 30%의 메모리와 6%의 CPU를 사용할 수 없습니다.
클라우드 제공업체마다 제한을 정의하는 방식이 다르지만, CPU의 경우 다음과 같은 값에 모두 동의하는 것 같습니다:
- 첫 번째 코어의 6%;
- 다음 코어의 1%(최대 2개 코어);
- 다음 2개 코어의 0.5%(최대 4개); 그리고
- 4코어 이상 코어의 0.25%.
메모리 제한은 제공업체마다 크게 다릅니다.
하지만 일반적으로 예약은 이 표를 따릅니다:
- 처음 4GB의 메모리 중 25%;
- 다음 4GB의 메모리 중 20%(최대 8GB);
- 다음 8GB 메모리의 10%(최대 16GB);
- 다음 112GB 메모리의 6%(최대 128GB); 그리고
- 128GB 이상 메모리의 2%.
이제 워커 노드 내에서 리소스가 어떻게 재분배되는지 알았으니, 이제 어떤 인스턴스를 선택해야 할까 하는 까다로운 질문을 할 차례입니다.
정답은 여러 가지가 있을 수 있으므로 워크로드에 가장 적합한 워커 노드에 집중하여 옵션을 제한해 보겠습니다.
프로파일링 앱
쿠버네티스에서는 컨테이너가 사용할 수 있는 메모리와 CPU의 양을 지정하는 두 가지 방법이 있다:
- 요청은 일반적으로 정상 운영 시 앱 사용량과 일치합니다.
- 제한은 허용되는 최대 리소스 수를 설정합니다.
쿠버네티스 스케줄러는 요청을 사용하여 클러스터에서 파드를 할당할 위치를 결정한다. 스케줄러는 사용량을 알지 못하기 때문에(파드가 아직 시작되지 않았기 때문에) 힌트가 필요하다. 이러한 "힌트"는 요청이며, 메모리용 요청과 CPU용 요청이 있을 수 있습니다.
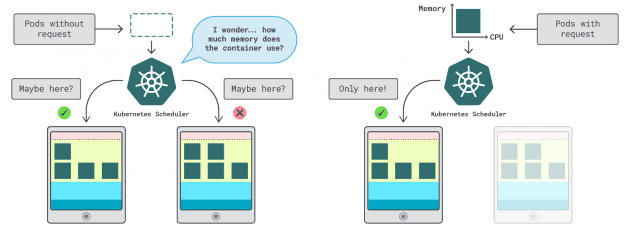
kubelet은 허용된 것보다 더 많은 메모리를 사용할 때 제한을 사용하여 프로세스를 중지합니다. 또한 허용된 것보다 더 많은 CPU 시간을 사용하는 경우 프로세스를 스로틀합니다.
그렇다면 요청과 한도에 적합한 값을 어떻게 선택할 수 있을까요?
워크로드 성능(예: 평균, 95번째 및 99번째 백분위수 등)을 측정하고 이를 제한 요청으로 사용할 수 있습니다. 프로세스를 간소화하기 위해 두 가지 편리한 도구를 사용하면 분석 속도를 높일 수 있습니다:
VPA는 메모리 및 CPU 사용률 데이터를 수집하고 회귀 알고리즘을 실행하여 배포에 대한 요청과 제한을 제안합니다. 공식 Kubernetes 프로젝트이며 값을 자동으로 조정하도록계측할 수도 있습니다. 컨트롤러가 요청과 제한을 YAML에서 직접 업데이트하도록 할 수도 있습니다.
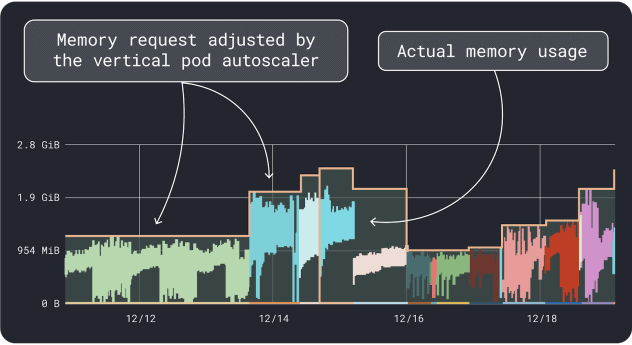
KRR은 비슷하게 작동하지만 내보낸 데이터를 활용합니다. Prometheus. 첫 번째 단계로, 워크로드를 계측하여 Prometheus 으로 메트릭을 내보내야 합니다. 모든 메트릭을 저장한 후에는 KRR을 사용하여 데이터를 분석하고 요청 및 제한을 제안할 수 있습니다.
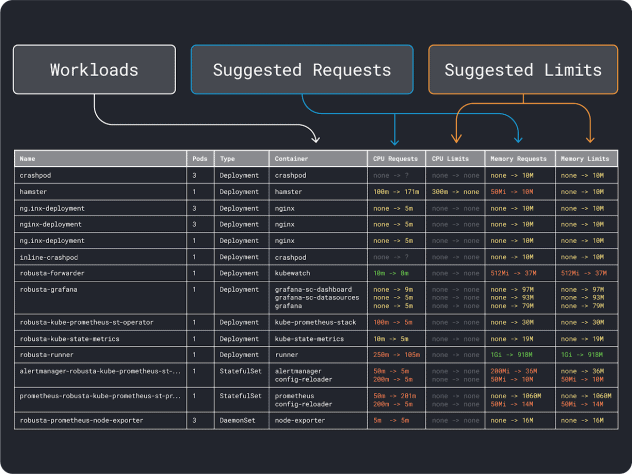
대략적인 리소스 요구 사항을 파악했다면 이제 인스턴스 유형을 선택할 수 있습니다.
인스턴스 유형 선택
워크로드에 2GB의 메모리 요청이 필요하고 최소 ~10개의 복제본이 필요하다고 예상한다고 가정해 보겠습니다.
'2GB * 10 = 20GB'보다 작은 대부분의 작은 인스턴스는 이미 배제할 수 있습니다. 이 시점에서 잘 작동할 수 있는 인스턴스를 추측할 수 있습니다: Linode 32GB를 선택하겠습니다.
그런 다음 해당 인스턴스에 배포할 수 있는 최대 파드 수(예: LKE의 경우 110개)로 메모리와 CPU를 나누어 메모리와 CPU의 개별 단위를 구할 수 있습니다.
예를 들어, 리노드 32GB의 CPU와 메모리 유닛은 다음과 같습니다:
- 메모리 장치 257MB(예: (32GB - 3.66GB 예약) / 110)
- CPU 유닛의 경우 71m(예: (8000m - 90m 예약) / 110)
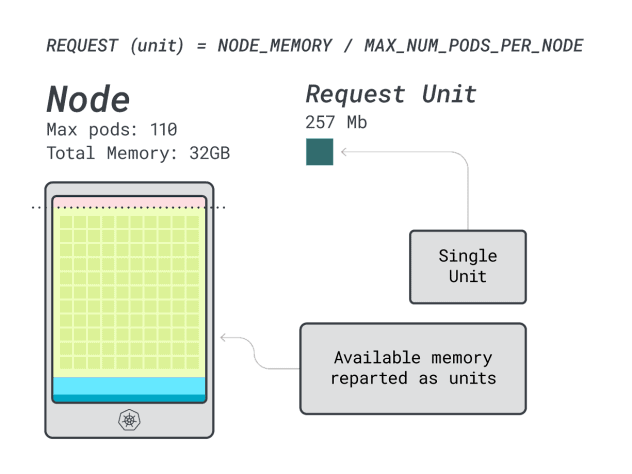
훌륭합니다! 마지막(그리고 마지막) 단계에서는 이러한 단위를 사용하여 노드에 얼마나 많은 워크로드가 들어갈 수 있는지 예측할 수 있습니다.
6GB와 1개의 vCPU 요청으로 Spring Boot를 배포한다고 가정하면, 이는 다음과 같이 해석됩니다:
- 6GB에 맞는 가장 작은 단위는 24단위(24 * 257MB = 6.1GB)입니다.
- 1개의 vCPU에 맞는 최소 유닛 수는 15개(15 * 71m = 1065m)입니다.
이 수치는 CPU가 부족해지기 전에 메모리가 부족해지며 클러스터에 최대 (110/24) 4개의 앱을 배포할 수 있음을 나타냅니다.
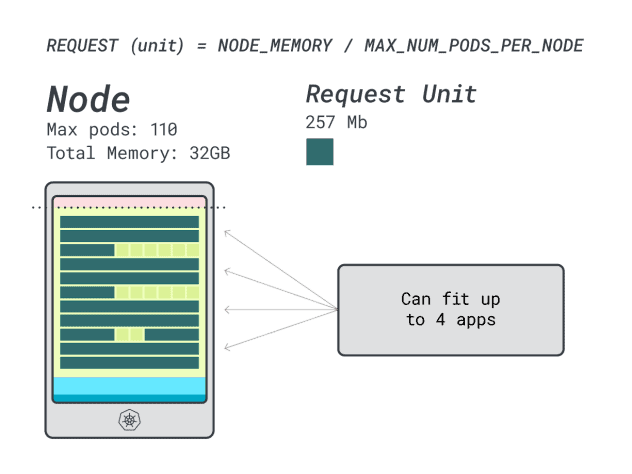
이 인스턴스에서 4개의 워크로드를 실행하는 경우 다음을 사용합니다:
- 24개 메모리 유닛 \* 4개 = 96개, 14개는 미사용(~12%)으로 남습니다.
- 15개의 vCPU 유닛 \* 4개 = 60개, 50개는 미사용(~45%)으로 남음
나쁘지 않지만 더 잘할 수 있을까요?
리노드 64GB 인스턴스(64GB / 16 vCPU)로 시도해 보겠습니다.
동일한 앱을 배포한다고 가정하면 숫자는 다음과 같이 변경됩니다:
- 메모리 유닛은 최대 527MB(즉, (64GB - 6.06GB 예약)/110)입니다.
- CPU 유닛은 최대 145m(즉, (16000m - 110m 예약) / 110)입니다.
- 6GB에 맞는 가장 작은 단위는 12단위(12 * 527MB = 6.3GB)입니다.
- 1개의 vCPU에 맞는 최소 유닛 수는 7개(7 * 145m = 1015m)입니다.
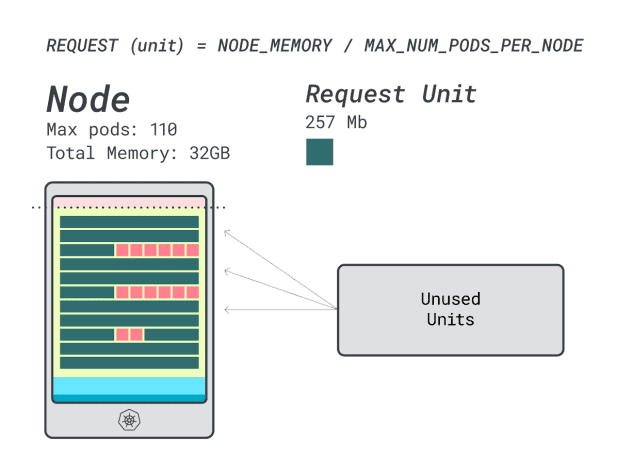
이 경우 몇 개의 워크로드를 수용할 수 있나요?
메모리를 최대로 사용하고 각 워크로드에 12개의 유닛이 필요하므로 최대 앱 수는 9개(즉, 110/12)입니다.
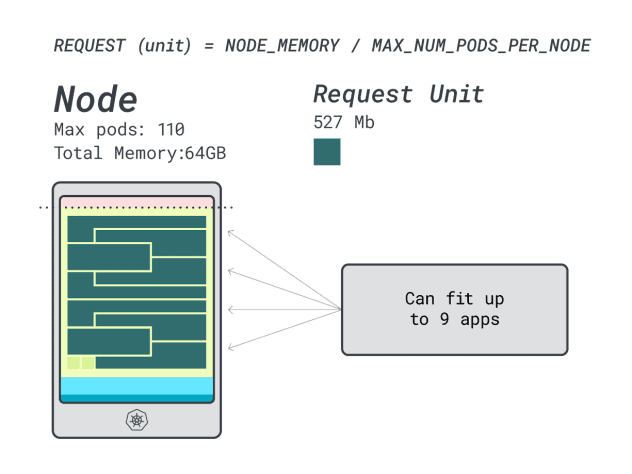
효율성/낭비를 계산해 보면 알 수 있습니다:
- 메모리 유닛 12개 \* 9개 = 108개, 2개는 미사용(~2%)으로 남습니다.
- 7개의 vCPU 유닛 \* 9 = 63개, 47개는 미사용(~42%)으로 남음
낭비되는 CPU의 수치는 이전 인스턴스와 거의 동일하지만 메모리 사용률은 크게 개선되었습니다.
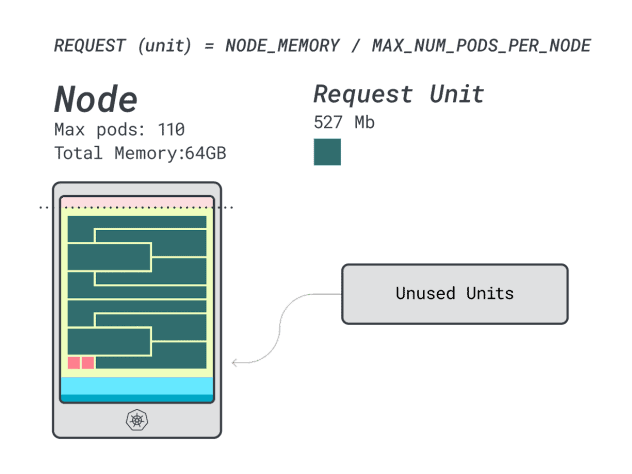
드디어 비용을 비교할 수 있게 되었습니다:
- 리노드 32GB 인스턴스는 최대 4개의 워크로드를 수용할 수 있습니다. 총 용량 기준, 각 포드의 비용은 월 $48입니다(즉, 인스턴스 비용을 워크로드 4개로 나눈 192달러).
- * 리노드 64GB 인스턴스는 최대 9개의 워크로드를 수용할 수 있습니다. 총 용량 기준, 각 포드의 비용은 월 $42.6입니다(즉, 인스턴스 비용 $384를 워크로드 9개로 나눈 값).
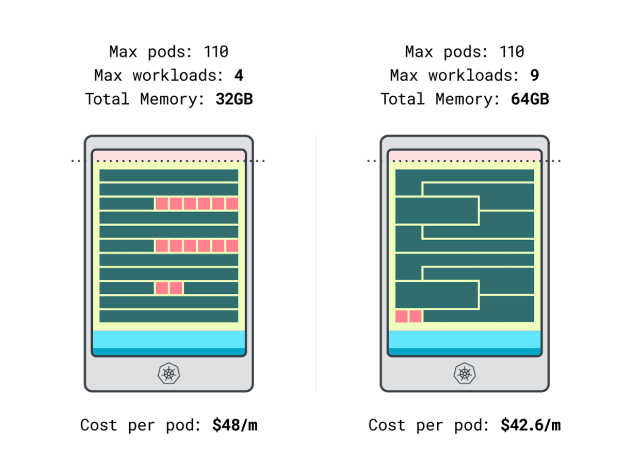
즉, 더 큰 인스턴스 크기를 선택하면 워크로드당 월 최대 6달러를 절약할 수 있습니다. 대단하죠!
계산기를 사용하여 노드 비교하기
하지만 더 많은 인스턴스를 테스트하고 싶다면 어떻게 해야 할까요? 이러한 계산을 하는 것은 많은 작업이 필요합니다.
Learnk8s 계산기를 사용하여 프로세스 속도를 높이세요.
계산기 사용의 첫 번째 단계는 메모리와 CPU 요청을 입력하는 것입니다. 시스템이 예약된 리소스를 자동으로 계산하고 사용률과 비용을 제안합니다. 몇 가지 유용한 추가 기능이 있습니다. 애플리케이션 사용량에 가까운 CPU 및 메모리 요청을 할당하는 것입니다. 애플리케이션이 때때로 더 높은 CPU 또는 메모리 사용량을 사용하더라도 괜찮습니다.
하지만 모든 파드가 모든 리소스를 한계까지 사용하면 어떻게 될까?
이는 과도한 커밋으로 이어질 수 있습니다. 중앙의 위젯은 CPU 또는 메모리 오버 커밋의 비율을 알려줍니다.
과도하게 커밋하면 어떻게 되나요?
- 메모리를 과도하게 커밋하면, kubelet은 파드를 퇴거시키고 클러스터의 다른 곳으로 이동시킨다.
- CPU를 과도하게 커밋하면 워크로드가 사용 가능한 CPU를 비례적으로 사용하게 됩니다.
마지막으로, 모든 노드에서 실행되는 파드를 모델링할 수 있는 편리한 메커니즘인 데몬셋과 에이전트 위젯을 사용할 수 있습니다. 예를 들어, LKE에는 Cilium과 CSI 플러그인이 DaemonSets로 배포되어 있습니다. 이러한 파드는 워크로드에서 사용할 수 없는 리소스를 사용하므로 계산에서 빼야 합니다. 위젯을 사용하면 바로 그렇게 할 수 있습니다!
요약
이 글에서는 LKE 클러스터의 워커 노드 가격을 책정하고 식별하는 체계적인 프로세스에 대해 살펴봤습니다.
쿠버네티스가 노드를 위해 리소스를 예약하는 방법과 이를 활용하기 위해 클러스터를 최적화하는 방법을 배웠습니다. 더 자세히 알아보고 싶으신가요? Akamai 클라우드 컴퓨팅 서비스와 제휴한 웨비나에 등록하여 실제 사례를 확인해 보세요.




내용