

TL;DR: In diesem Beitrag erfahren Sie, wie Sie den besten Knoten für Ihren Kubernetes-Cluster auswählen, bevor Sie einen Code schreiben.
Wenn Sie einen Kubernetes-Cluster erstellen, ist eine der ersten Fragen, die Sie sich vielleicht stellen: "Welche Art von Worker Nodes soll ich verwenden und wie viele davon?"
Oder wenn Sie einen verwalteten Kubernetes-Dienst wie Linode Kubernetes Engine (LKE) verwenden, sollten Sie acht Linode 2 GB oder zwei Linode 8 GB Instanzen verwenden, um die gewünschte Rechenkapazität zu erreichen?
Erstens können nicht alle Ressourcen in den Arbeitsknoten für die Ausführung von Workloads verwendet werden.
Kubernetes-Knoten-Reservierungen
In einem Kubernetes-Knoten sind CPU und Speicher unterteilt:
- Das Betriebssystem
- Kubelet, CNI, CRI, CSI (und Systemdämonen)
- Hülsen
- Schwellenwert für die Räumung
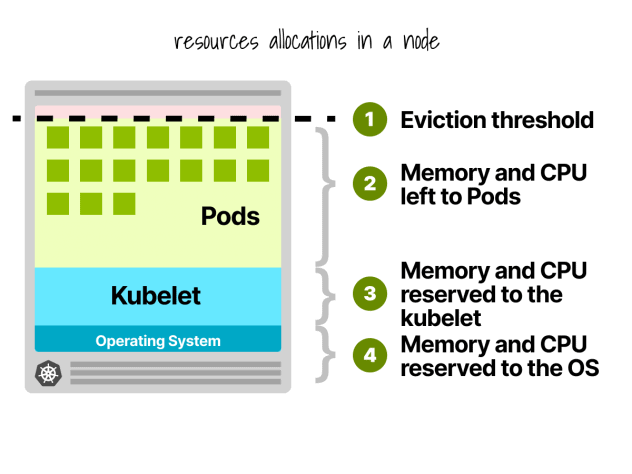
Lassen Sie uns ein kurzes Beispiel nennen.
Stellen Sie sich vor, Sie haben einen Cluster mit einer einzelnen Linode 2GB Compute Instance, oder 1 vCPU und 2GB RAM.
Die folgenden Ressourcen sind für das Kubelet und das Betriebssystem reserviert:
- -500 MB Speicher.
- -60m der CPU.
Darüber hinaus sind 100 MB für die Auslagerungsschwelle reserviert.
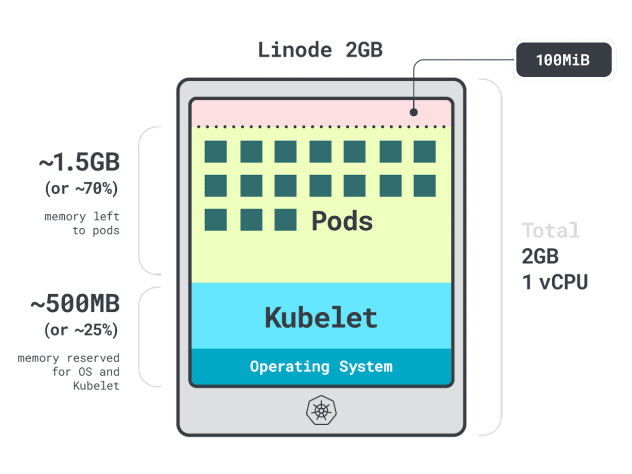
Insgesamt sind das 30 % des Arbeitsspeichers und 6 % der CPU, die Sie nicht nutzen können.
Jeder Cloud-Anbieter hat seine eigene Art, die Grenzen zu definieren, aber für die CPU scheinen sie sich alle auf die folgenden Werte zu einigen:
- 6% des ersten Kerns;
- 1% des nächsten Kerns (bis zu 2 Kerne);
- 0,5% der nächsten 2 Kerne (bis zu 4); und
- 0,25 % aller Kerne über vier Kerne.
Was die Speicherbegrenzung betrifft, so variiert diese stark von Anbieter zu Anbieter.
Aber im Allgemeinen folgt die Reservierung dieser Tabelle:
- 25 % der ersten 4 GB des Speichers;
- 20% der folgenden 4 GB Speicher (bis zu 8 GB);
- 10 % der folgenden 8 GB Speicher (bis zu 16 GB);
- 6 % der nächsten 112 GB Speicher (bis zu 128 GB); und
- 2% des Speichers über 128 GB.
Da Sie nun wissen, wie die Ressourcen innerhalb eines Arbeitsknotens aufgeteilt werden, ist es an der Zeit, die schwierige Frage zu stellen: Welche Instanz sollten Sie wählen?
Da es viele richtige Antworten geben könnte, sollten wir unsere Optionen einschränken, indem wir uns auf den besten Arbeitsknoten für Ihre Arbeitslast konzentrieren.
Apps profilieren
In Kubernetes gibt es zwei Möglichkeiten, um festzulegen, wie viel Arbeitsspeicher und CPU ein Container nutzen kann:
- Die Anfragen entsprechen in der Regel dem App-Verbrauch im Normalbetrieb.
- Limits legen die maximale Anzahl der erlaubten Ressourcen fest.
Der Kubernetes-Scheduler verwendet Anfragen, um zu bestimmen, wo der Pod im Cluster zugewiesen werden soll. Da der Scheduler den Verbrauch nicht kennt (der Pod ist noch nicht gestartet), benötigt er einen Hinweis. Diese "Hinweise" sind Anfragen; Sie können eine für den Speicher und eine für die CPU haben.
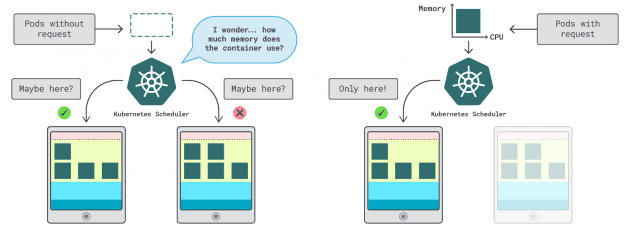
Das Kubelet verwendet Grenzwerte, um den Prozess zu stoppen, wenn er mehr Speicher als erlaubt verbraucht. Es drosselt den Prozess auch, wenn er mehr CPU-Zeit als erlaubt verbraucht.
Aber wie wählt man die richtigen Werte für Anfragen und Grenzwerte?
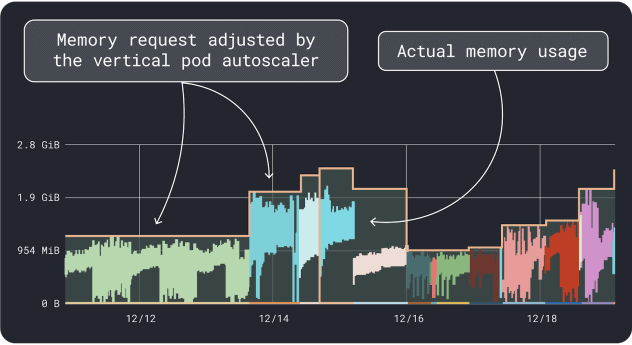
Sie können Ihre Workload-Leistung messen (d. h. Durchschnitt, 95. und 99. Perzentil usw.) und diese als Anforderungen und Grenzwerte verwenden. Um den Prozess zu erleichtern, können zwei praktische Tools die Analyse beschleunigen:
Der VPA sammelt die Daten zur Speicher- und CPU-Auslastung und führt einen Regressionsalgorithmus aus, der Anforderungen und Grenzwerte für Ihre Bereitstellung vorschlägt. Es ist ein offizielles Kubernetes-Projekt und kann auch instrumentiert werden, um die Werte automatisch anzupassen -Sie können den Controller die Anforderungen und Grenzen direkt in Ihrer YAML aktualisieren lassen.
KRR funktioniert ähnlich, aber es nutzt die Daten, die Sie über Prometheus. In einem ersten Schritt sollten Sie Ihre Workloads so instrumentieren, dass sie Metriken an Prometheus exportieren. Sobald Sie alle Metriken gespeichert haben, können Sie KRR verwenden, um die Daten zu analysieren und Anforderungen und Grenzen vorzuschlagen.
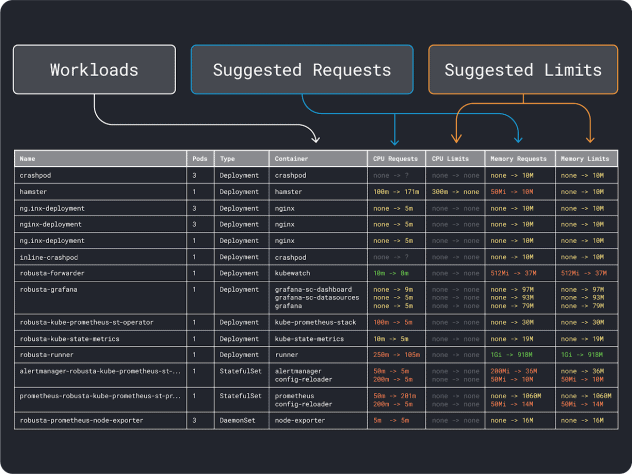
Wenn Sie eine Vorstellung von den (groben) Ressourcenanforderungen haben, können Sie schließlich einen Instanztyp auswählen.
Auswählen eines Instanztyps
Stellen Sie sich vor, Sie schätzen, dass Ihre Arbeitslast 2 GB an Speicheranforderungen erfordert, und Sie schätzen, dass Sie mindestens ~10 Replikate benötigen.
Die meisten kleinen Instanzen mit weniger als "2 GB * 10 = 20 GB" können Sie bereits ausschließen. An diesem Punkt können Sie eine Instanz erraten, die gut funktionieren könnte: Nehmen wir Linode 32GB.
Als Nächstes können Sie Speicher und CPU durch die maximale Anzahl von Pods teilen, die auf dieser Instanz eingesetzt werden können (d. h. 110 in LKE), um eine diskrete Einheit von Speicher und CPU zu erhalten.
Die CPU- und Speichereinheiten für die Linode 32 GB sind zum Beispiel:
- 257 MB für die Speichereinheit (d. h. (32 GB - 3,66 GB reserviert) / 110)
- 71m für die CPU-Einheit (d.h. (8000m - 90m reserviert) / 110)
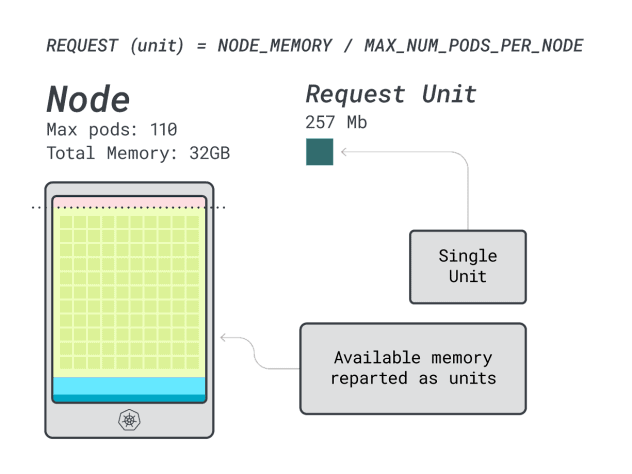
Ausgezeichnet! Im letzten (und abschließenden) Schritt können Sie diese Einheiten verwenden, um abzuschätzen, wie viele Arbeitslasten auf den Knoten passen können.
Angenommen, Sie möchten ein Spring Boot mit 6 GB und 1 vCPU bereitstellen, bedeutet dies:
- Die kleinste Anzahl von Einheiten, in die 6 GB passen, ist 24 Einheiten (24 * 257 MB = 6,1 GB)
- Die kleinste Anzahl von Einheiten, die auf 1 vCPU passt, ist 15 Einheiten (15 * 71m = 1065m)
Die Zahlen deuten darauf hin, dass Ihnen der Speicher ausgeht, bevor Ihnen die CPU ausgeht, und Sie können höchstens (110/24) 4 Anwendungen im Cluster einsetzen.
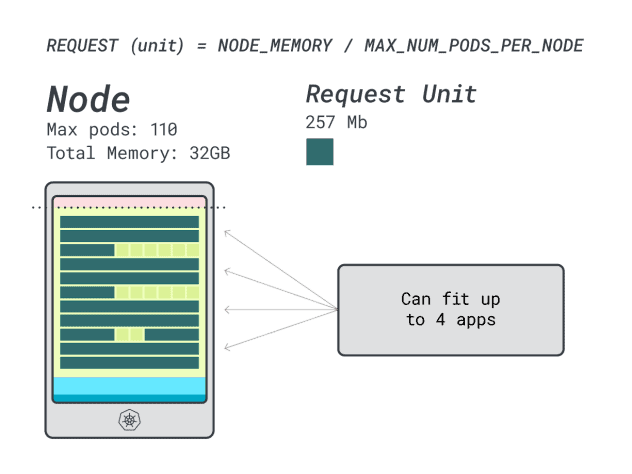
Wenn Sie vier Workloads auf dieser Instanz ausführen, verwenden Sie:
- 24 Speichereinheiten \* 4 = 96 Einheiten und 14 bleiben ungenutzt (~12%)
- 15 vCPU-Einheiten \* 4 = 60 Einheiten und 50 bleiben ungenutzt (~45%)
Nicht schlecht, aber können wir es besser machen?
Versuchen wir es mit einer Linode 64 GB Instanz (64GB / 16 vCPU).
Angenommen, Sie möchten dieselbe Anwendung bereitstellen, ändern sich die Zahlen zu:
- Eine Speichereinheit ist ~527MB (d.h. (64GB - 6,06GB reserviert) / 110).
- Eine CPU-Einheit ist ~145m (d.h. (16000m - 110m reserviert) / 110).
- Die kleinste Anzahl von Einheiten, die in 6 GB passt, ist 12 Einheiten (12 * 527 MB = 6,3 GB).
- Die kleinste Anzahl von Einheiten, die auf eine vCPU passt, ist 7 Einheiten (7 * 145m = 1015m).
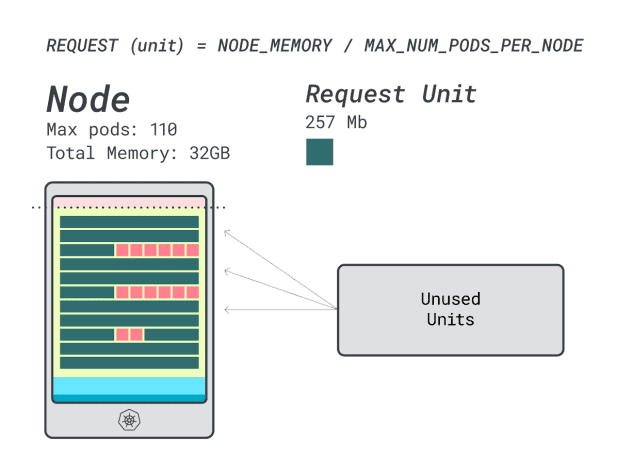
Wie viele Workloads können Sie in dieser Instanz unterbringen?
Da Sie den Arbeitsspeicher voll ausschöpfen werden und jede Arbeitslast 12 Einheiten benötigt, beträgt die maximale Anzahl von Anwendungen 9 (d. h. 110/12).
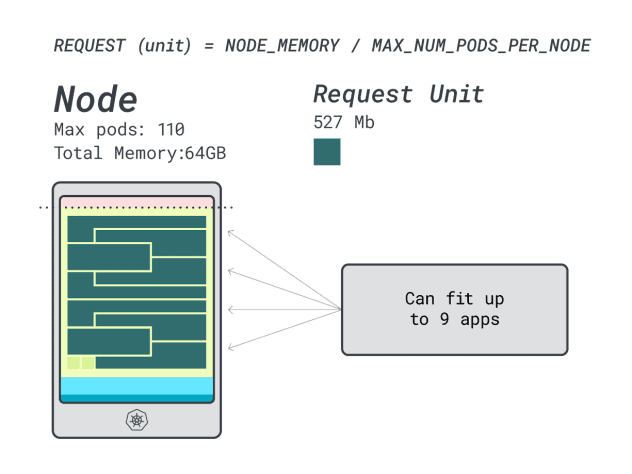
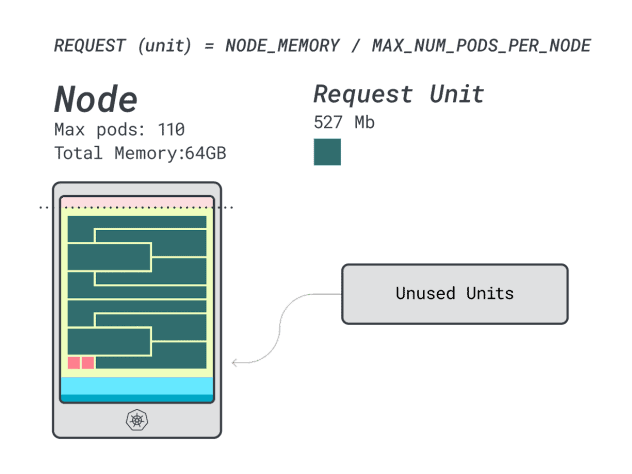
Wenn Sie die Effizienz/Verschwendung berechnen, werden Sie feststellen:
- 12 Speichereinheiten \* 9 = 108 Einheiten und 2 bleiben ungenutzt (~2%)
- 7 vCPU-Einheiten \* 9 = 63 Einheiten und 47 bleiben ungenutzt (~42 %)
Während die Zahlen für die verschwendete CPU fast identisch mit denen der vorherigen Instanz sind, ist die Speichernutzung drastisch verbessert.
Wir können endlich die Kosten vergleichen:
- Die Linode 32 GB Instanz kann maximal 4 Arbeitslasten aufnehmen. Bei der Gesamtkapazität kostet jeder Pod 48 $/Monat (d. h. 192 $ Kosten für die Instanz geteilt durch vier Arbeitslasten).
- *Die Linode 64 GB Instanz kann bis zu 9 Arbeitslasten aufnehmen. Bei der Gesamtkapazität kostet jeder Pod 42,6 $/Monat (d. h. 384 $ Kosten für die Instanz geteilt durch neun Workloads).
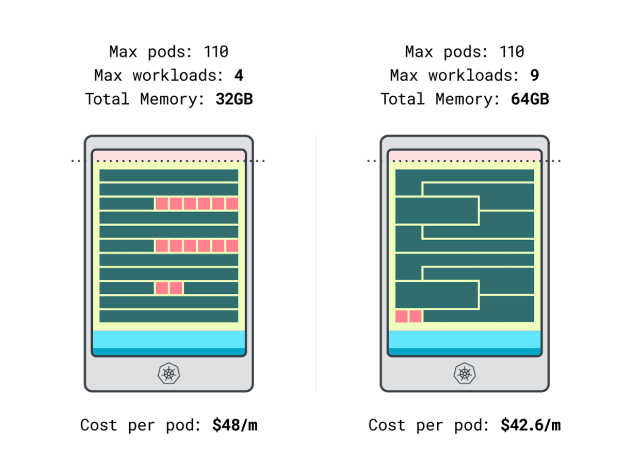
Mit anderen Worten: Wenn Sie sich für die größere Instanzgröße entscheiden, können Sie bis zu 6 Dollar pro Monat und Arbeitslast sparen. Großartig!
Vergleichen von Knoten mithilfe des Rechners
Was aber, wenn Sie mehr Instanzen testen wollen? Diese Berechnungen sind eine Menge Arbeit.
Beschleunigen Sie den Prozess mit dem learnk8s-Rechner.
Der erste Schritt bei der Verwendung des Rechners ist die Eingabe Ihrer Speicher- und CPU-Anforderungen. Das System berechnet automatisch die reservierten Ressourcen und schlägt Auslastung und Kosten vor. Es gibt einige zusätzliche hilfreiche Funktionen: Weisen Sie CPU- und Speicheranforderungen nahe an der Anwendungsnutzung zu. Wenn die Anwendung gelegentlich eine höhere CPU- oder Speichernutzung aufweist, ist das in Ordnung.
Aber was passiert, wenn alle Pods alle Ressourcen bis an ihre Grenzen nutzen?
Dies könnte zu einer übermäßigen Beanspruchung führen. Das Widget in der Mitte zeigt Ihnen den Prozentsatz der CPU- oder Speicherüberlastung an.
Was passiert, wenn man sich zu viel vornimmt?
- Wenn Sie zu viel Speicher zuweisen, wird das Kubelet die Pods aus dem Cluster entfernen und sie an einen anderen Ort verschieben.
- Wenn Sie die CPU zu stark beanspruchen, nutzen die Arbeitslasten die verfügbare CPU anteilig.
Schließlich können Sie das DaemonSets- und Agent-Widget verwenden, ein praktischer Mechanismus zur Modellierung von Pods, die auf allen Ihren Knoten laufen. Bei LKE sind beispielsweise das Cilium- und das CSI-Plugin als DaemonSets implementiert. Diese Pods verwenden Ressourcen, die Ihren Workloads nicht zur Verfügung stehen, und sollten von den Berechnungen abgezogen werden. Mit dem Widget können Sie genau das tun!
Zusammenfassung
In diesem Artikel haben Sie einen systematischen Prozess zur Ermittlung des Preises und der Worker Nodes für Ihren LKE-Cluster kennengelernt.
Sie haben gelernt, wie Kubernetes Ressourcen für Knoten reserviert und wie Sie Ihren Cluster optimieren können, um davon zu profitieren. Möchten Sie mehr erfahren? Melden Sie sich für unser Webinar in Zusammenarbeit mit Akamai Cloud Computing Services an, um dies in Aktion zu erleben.




Kommentare