

かつては実現不可能だったことが実用化されただけで、利用方法や関連技術の進歩が突然飛躍したように見えることはよくある。ビッグデータ・アプリケーションの増加は、クラウド・コンピューティングの普及と密接に関連している。ここでは、ビッグデータとは何か、なぜ今日重要なのか、そしてNoSQLデータベースと連動してどのように進化してきたかに焦点を当てよう。ビッグデータについて語るとき、私たちが扱うのは、関連する何かを見つけるために見る、あるいは分析することができる大量の情報である。
ビッグデータには、一般的に3つの特徴があり、それぞれ3つのVs.で示されています。
- ボリューム- 私たちは多くのデータを持っています。
- Velocity- 私たちのデータは高速で送られてきます。
- 多様性- 私たちのデータは様々な形で存在しています。
ここでは、大量のデータを取得する方法、データの種類、そしてデータから得られる価値について説明します。
結論の導き方
小さなデータセットでは、現実の世界を表現する上で信頼性に欠けるため、根本的なパターンを見つけるためには、大きなデータセットが必要なのです。 例えば、10人を対象にアンケートを取ったとします。そのうち8人がアンドロイド携帯を持っていて、2人がiPhoneを持っているとします。この小さなサンプル数では、アップルの市場シェアは20%に過ぎないと推定されるでしょう。これは、現実の世界をよく表しているとは言えません。
また、複数のデモグラフィックやロケーションから情報を得ることも重要です。ペンシルベニア州フィラデルフィアの10人を調査しても、世界や米国、あるいはペンシルベニア州全体について多くを語ることはできません。つまり、信頼できる良いデータを得るには、多くのデータが必要なのです。より広範な調査であればあるほど、それを分解して結論を導き出すことができるのです。
アンケートを10人から100人に増やし、参加者の年齢も記録してみましょう。これで、より大きなサンプルサイズから、より多くのデータを収集することができます。さて、その結果、40人がAndroid携帯を、60人がiPhoneを持っていることがわかったとします。これはまだ非常に小さなサンプルですが、参加者が10倍になることで、結果が80ポイントも大きく変動したことがわかります。しかし、これは1つの分野のデータだけを見た場合です。年齢と携帯電話の選択肢を記録しているので、10~20歳のグループと21~30歳のグループでは、比率が大きく異なることが分かるかもしれません。
すべてはアルゴリズムのために
ビッグデータでは、さまざまな形式で大量に送られてくるデータを高速に処理しています。このデータから基本的なパターンを見つけ出し、実世界を反映した正確なモデルを作成することができます。なぜ、このようなことが重要なのでしょうか。正確なモデルは、予測やアルゴリズムの開発・改良を可能にします。
ビッグデータが日常生活で使われている最も一般的な例は、単純なものであり、時に議論を呼ぶこともある、レコメンデーションエンジンである。"もしあなたがXを好きなら、おそらくYも好きでしょう!"。これはマーケティングや広告の観点からは確かに有用だが、使用例としてはこれだけでは到底足りない。ビッグデータとアルゴリズムは、自動運転車から病気の早期発見まで、あらゆるものに力を発揮します。
この短いデータ収集の例では、100人に止まりましたが、本当に良いデータを得ようとするならば、何千、何百万もの様々な属性のソースが必要です。これでは、たとえサンプル数を増やし、結果を迅速に取り込めたとしても、本当の意味での「ビッグデータ」とは言えません。3つのVのうちの1つである「多様性」が欠落しているのです。そして、多様性こそがデータの大部分を生み出す源なのです。
データバリエーション
収集するデータの種類は、基本的に3つに分類することができます。構造化データ、半構造化データ、非構造化データです。構造化されたデータとは、上記のアンケート調査と同じようなものです。あらかじめ定義されたスキーマがあり、入力は厳格な構造に当てはまります。このタイプのデータは、行と列を扱うように設計されているため、SQLを使用するRDBMSに最適です。SQLデータベース以外の構造化データには、通常、csvファイルやスプレッドシートが含まれます。

存在するデータの大部分は、私たちの日々の活動から、さまざまな方法で多くの異なるソースからもたらされています。ソーシャルメディアの投稿、購買履歴、ブラウジング、Cookie。あらゆる行動が、年齢、居住地、性別、配偶者の有無など、多数の属性を持つ個人のプロファイルを構築することができます。ここでは表面だけを取り上げていますが、次の点にだけ注目すればよいのです。産業界は正確な結論を出すために多くのデータを収集しており、このデータの大部分はあらかじめ定義され、構造化された形式ではありません。ビッグデータでは、通常、半構造化および非構造化形式のデータを扱います。
アプリケーションログや電子メールは、半構造化データの一例です。このようなデータを半構造化データと呼ぶのは、行と列が厳密ではないものの、データのフォーマットには一般的なパターンが存在するためです。半構造化データのファイルタイプとして最も一般的なのは、JSONとXMLの2つです。非構造化データとは、構造化されていない、あるいは半構造化されていないデータのことで、私たちのデータの大部分を占めています。非構造化データの一般的な例としては、ソーシャルメディアの投稿、オーディオファイルやビデオファイル、画像、その他のドキュメントなどがあります。
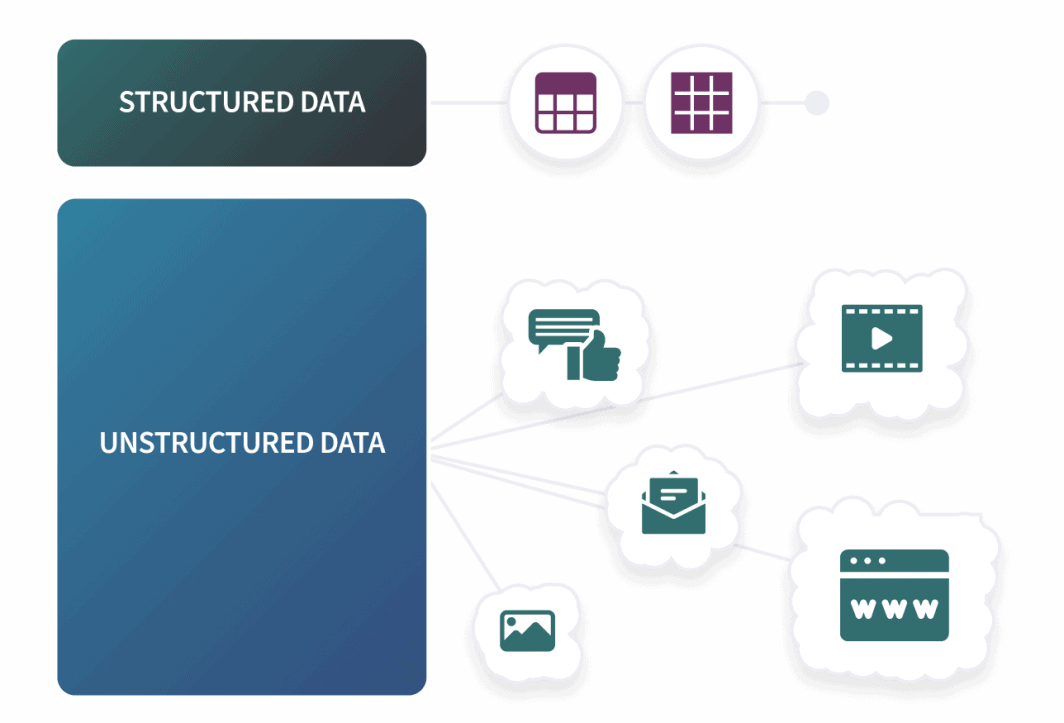
しかし、より多くのデータを取得するためには、構造化されたデータだけでなく、より多くのデータを取り込むことができるシステムが必要です。そこで、NoSQLデータベースの出番となるわけです。
ビッグデータとNoSQL
ビッグデータという概念は1980年代から知られていましたが、今日最も急成長している技術の多くと同様に、2000年代半ばに大きな一歩を踏み出しました。2006年にApache 、Hadoopがリリースされると、そのマイルストーンが打ち出されました。Hadoopは、大規模なデータセットを確実に処理するために設計された、オープンソースのソフトウェアフレームワークです。
コアとなるコンポーネントには、HDFS(Hadoop Distributed File System)やYARN(Yet Another Resource Negotiator)などがあります。HDFSは高速で耐障害性の高いファイルシステムで、YARNはジョブのスケジューリングとリソース管理を行う。ほとんどの場合、HDFSの上で動作するのは、列指向の非リレーショナルデータベースであるHBaseです。HBaseはNoSQLの緩やかな定義に当てはまるが、他の一般的なデータベースとは十分に異なるため、通常MongoDBやCassandra(別のApache プロジェクト)と同じリストには載らないだろう。
HDFSと連携するHBaseは、数十億行の大量データを格納でき、スパースデータにも対応する。しかし、制限がないわけではありません。HBaseはHDFSに依存し、ハードウェア要件が厳しく、ネイティブなクエリ言語がない。MongoやCassandraとは異なり、HBaseはプライマリ・レプリカ・アーキテクチャに依存しているため、単一障害点となる可能性があります。
しかし、冒頭から、ビッグデータとNoSQLがマッチする理由が見えてくる。もう一度、Vsを実行してみましょう。
- ボリューム- ビッグデータには巨大なデータベースが必要であり、巨大なデータベースには水平方向のスケーリングが必要です。SQLデータベースでも水平方向の拡張は可能ですが、多くの場合、大きな制約があります。しかし、スキーマレスNoSQLデータベースはこの点で優れています。
- 速度- NoSQLデータベースは、SQLデータベースのような一貫性と検証を欠いていますが、大量のデータを素早く取り込むために必要な生の書き込み速度を備えています。
- 多様性- ビッグデータには非構造化データを扱えるシステムが必要であり、MongoDBのようなスキーマレスNoSQLデータベースはこのタスクに適している。
NoSQLデータベースはビッグデータ専用というわけではありませんが、互いに歩調を合わせて発展してきた理由がよくわかります。ビッグデータが減速する兆しはなく、2009年に初めてリリースされたNoSQLのMongoDBは、市場で最も速く成長しているデータベースの1つです。



コメント