

We often find a seemingly sudden leap in usage and related technology advancements simply because what was once unfeasible is now practical. The increase in Big Data applications follows closely behind the spread of cloud computing. Let’s focus on what Big Data is, why it matters today, and how it has evolved in tandem with NoSQL databases. When we talk about Big Data, we’re dealing with massive quantities of information that we can look at, or analyze, to find something relevant.
Big Data typically has three characteristics each marked by the 3 Vs.
- Volume – We have a lot of data.
- Velocity – Our data is coming in fast.
- Variety – Our data is in many different forms.
Let’s dive into how we get so much data, types of data, and the value we can derive from it.
Drawing Conclusions
We need large sets of data to find underlying patterns because small sets of data are unreliable in representing the real world. Imagine taking a survey of 10 people: eight of them have Android phones, two have iPhones. With this small sample size, you would extrapolate that Apple only has a 20% market share. This is not a good representation of the real world.
It’s also important to get information from multiple demographics and locations. Surveying 10 people from Philadelphia, Pennsylvania doesn’t tell us much about the world, the United States, or even the state of Pennsylvania as a whole. In short, getting good, reliable data requires a lot of it. The broader the study, the more we can break it down and draw conclusions.
Let’s up our survey from 10 to 100 and also record the age of the participants. Now we’re collecting more data from a larger sample size. Now, let’s say the results show that 40 people have Android phones and 60 have iPhones. This is still a very small sample but we can see that a 10x increase in participants resulted in a significant 80 point swing in our results. But that’s only considering one field of data from our set. Since we recorded our participants’ age as well as phone choice, we might find that groups aged 10-20 or 21-30 have a very different ratio.
It’s All About the Algorithm
Big Data has us processing large volumes of data coming in fast and in a variety of formats. From this data, we’re able to find underlying patterns that allow us to create accurate models that reflect the real world. Why does this matter? Accurate models allow us to make predictions and develop or improve algorithms.
The most common example of Big Data at work in our daily lives is something simple and sometimes controversial – recommendation engines. “If you like X, you’ll probably like Y, too!” This is certainly useful from a marketing and advertising perspective, but this is far from the only use case. Big Data and algorithms power everything from self-driving cars to early disease detection.
In our short example of data collection, we stopped at 100 people, but if you really want good data, you need thousands or millions of sources with a magnitude of different attributes. This still wouldn’t truly qualify as “Big Data,” even if we expanded the sample size and set up a rapid ingest of results. We’d be missing one of the three Vs, Variety, and that’s where a bulk of our data comes from.
Data Varieties
We can classify the type of data we collect into three basic categories: Structured, Semi-Structured, and Unstructured. Structured data would be similar to our survey above. We have a predefined schema and our input will fit into a rigid structure. This type of data is perfect for RDBMSs using SQL since they are designed to work with rows and columns. Outside of SQL databases, structured data typically includes csv files and spreadsheets.

A vast majority of the data that exists is coming from a lot of different sources from our day to day activities in a lot of different ways. Social media posts, purchasing history, browsing and cookies: Every action can build a profile for an individual with numerous attributes such as age, location, gender, marital status, and beyond. We’re just scratching the surface here but we only need to focus on the following: industries are collecting a lot of data to draw accurate conclusions and a vast majority of this data is not in predefined, structured formats. For Big Data, we’re usually working with Semi-Structured and Unstructured forms of data.
Application logs or emails are examples of semi-structured data. We call this semi-structured because while it’s not in rigid rows and columns, there is a general pattern to how this data is formatted. Two of the most common file types of semi-structured data are JSON and XML. Unstructured data can be almost anything that isn’t structured or semi-structured, and as we can imagine, this makes up a vast majority of our data. Common examples of unstructured data include social media posts, audio and video files, images, and other documents.
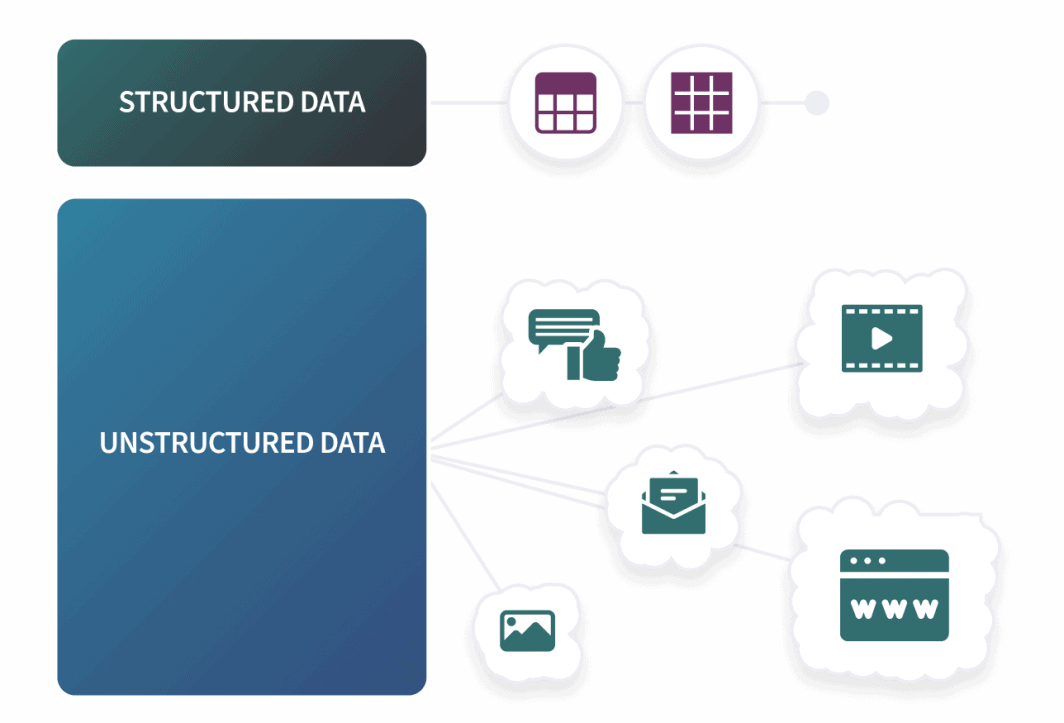
Our phone choice survey still works as an analytical demonstration : The more data we have, the more accurately our conclusions will reflect the real world, but to actually get more data we need to have a system capable of ingesting more than just structured data. This is where NoSQL databases enter the equation.
Big Data and NoSQL
The concept of big data has been known since the 1980s, and like many of today’s fastest-growing technologies, it took a major step forward in the mid 2000s. A milestone hit when Apache released Hadoop in 2006. Hadoop is an open source software framework designed to reliably process large datasets.
Some of the core components include HDFS (Hadoop Distributed File System) and YARN (Yet Another Resource Negotiator). HDFS is a fast and fault tolerant file system and YARN handles job scheduling and resource management. Running on top of HDFS in most cases is HBase, a column-oriented non-relational database. HBase fits the loose definition of NoSQL but it’s different enough from the other popular databases that it won’t normally appear on the same lists as MongoDB or Cassandra (another Apache project).
HBase in tandem with HDFS can store massive amounts of data in billions of rows and supports sparse data. However, it’s not without its limitations. HBase is dependent on HDFS, has steep hardware requirements, and lacks a native query language. Unlike Mongo and Cassandra, HBase also relies on primary-replica architecture that can result in a single point of failure.
But right from the beginning, we can see why Big Data and NoSQL are a match. Let’s run through the Vs again.
- Volume – Big Data requires a massive database, and a massive database requires horizontal scaling. SQL databases can, often with significant limitations, scale horizontally, but this is where schemaless NoSQL databases excel.
- Velocity – NoSQL databases lack the consistency and validation of SQL databases, but again the raw write speed we need to ingest a lot of data, quickly.
- Variety – Big Data requires a system capable of handling unstructured data and schemaless NoSQL databases like MongoDB are well suited for the task.
NoSQL databases are not exclusively used for Big Data, but we can see why they developed in lockstep with one another. There are no signs of a Big Data slowdown, and the NoSQL MongoDB, first released in 2009, is one of the fastest growing databases on the market.



Comments