


Modern cloud storage is typically offered as three different types of solutions. The first type, and the one that is generally most familiar, is file-based storage. File-based storage is simply data stored in files within a hierarchy on a storage medium. In recent years, two other types of storage have come into popular usage: block storage and object storage. Block storage manages data by breaking it into smaller pieces, or blocks, within the hardware. Object storage stores data as immutable blobs with detailed metadata and a unique identifier in a flat structure.
All three types of storage have their uses and it is important to understand what type of storage to use and when to use it in your application. In this post, we will focus on expanding your knowledge of S3-compatible object storage and understanding when it is the appropriate solution to use in your architecture.
Types of Storage
File-Based Storage stores data as a single piece of information inside a directory, i.e. a folder. Imagine a file cabinet full of folders organized in alphabetical order. When you want to retrieve data about your garden, you simply go to the “G” section in your file cabinet.
Block storage chunks up data into smaller segments called blocks, and each block of data is given a unique identifier for retrieval. Block storage is like taking each of the pages out of a book and storing them in a separate non-linear fashion. When you need to reassemble the book, you can do so by page number.
Object storage is a flat structure in which files are broken up into individual units called objects and given a unique identifier. Object storage is like using valet parking; keys are stored with location information and that data can be used to retrieve a car from the parking garage. The key is the identifier, the location is the metadata, and the object is the car.
First, we should define object storage a little more clearly from a business and technical perspective. From a business perspective, object storage is a system of data storage that’s designed to be massively scalable, durable, and cost-effective. From a technical perspective, object storage accomplishes this goal by storing data as objects, decoupling the stored objects from other infrastructure, and allowing the stored data to be programmatically accessible via an HTTP-based interface. Understanding when and why to use object storage in your application can translate to savings from both an operational and a budgetary standpoint.
Let’s dig a little deeper to get a better understanding of what an object is in Object Storage. What does it mean when we say that we store data as objects? Object storage was built to handle large amounts of unstructured data with associated metadata and indexing. So, an object can be defined as data which is stored as a blob or object, the metadata around that object, and a unique identifier for each object.
In the cloud, such objects are stored in structures commonly referred to as buckets and all of the objects can be directly accessed via an HTTP request. This means that all your data can be accessed programmatically from the microservices that comprise your architecture which translates to massive scalability across your applications and low-priced storage costs.
Accessing data via HTTP requests is one of the core tenets of object storage services in the cloud today. AWS pioneered the use of object storage in cloud computing by creating the Simple Storage Service and an associated API, which has become known as the S3 API. Emulating the functionality of the S3 API has become the defacto standard for implementing object storage in the cloud.
Linode built its object storage service using ceph object gateway, which provides compatibility with the basic access model of the S3 API. This means that you can write S3 compliant workloads for multiple clouds using a common API. In other words, data that is currently being hosted in Amazon S3, Google Cloud Storage, Azure Blob Storage, or Digital Ocean Spaces can also be stored in Linode Object Storage without the need to change the interface . Taking advantage of a common API standard can help your business maximize it’s multi-cloud strategy.
Now that we understand the differences between types of storage and how an S3 compatible API can provide multi-cloud functionality, let’s examine some of the most common use cases for incorporating object storage into your production architecture. Recall that object storage provides massively scalable, cost-effective storage for unstructured data across a wide variety of applications and services.
Use Cases:
Backups and Disaster Recovery: Object storage is the perfect destination for backups across your organization. There are a variety of services that take advantage of a backup strategy that utilizes Linode Object Storage including SHIELD Cloud.
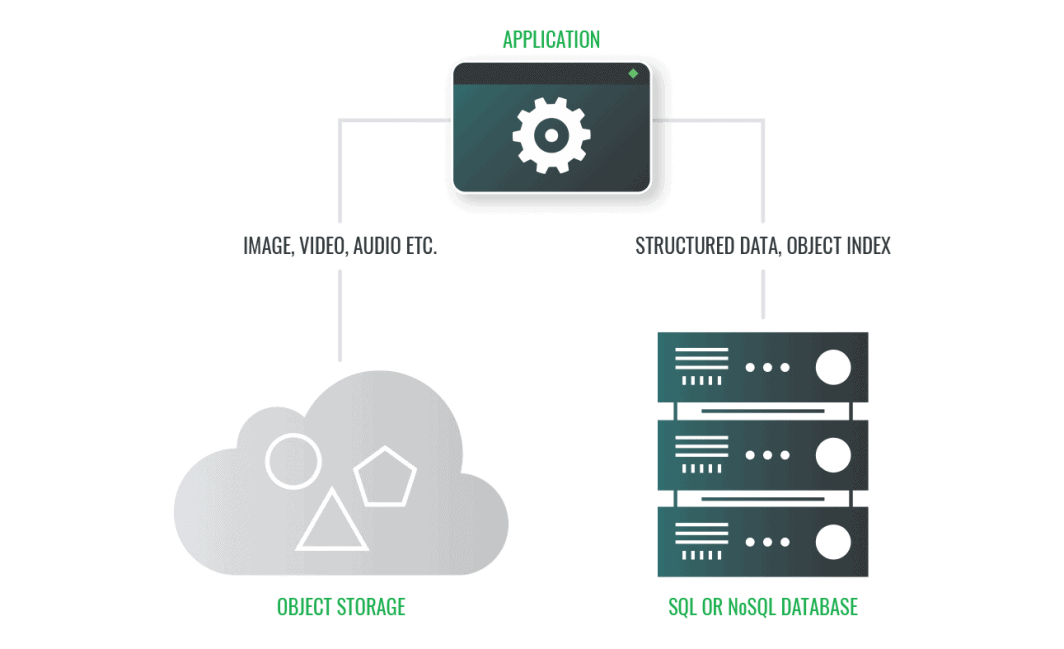
Static Assets: Deploy serverless web applications using react and S3-compatible object storage. You can decouple your static assets from your compute architecture which allows for scalability and reduced storage costs while maintaining high availability. Object storage is a great use case for static websites that do not require a compute environment.
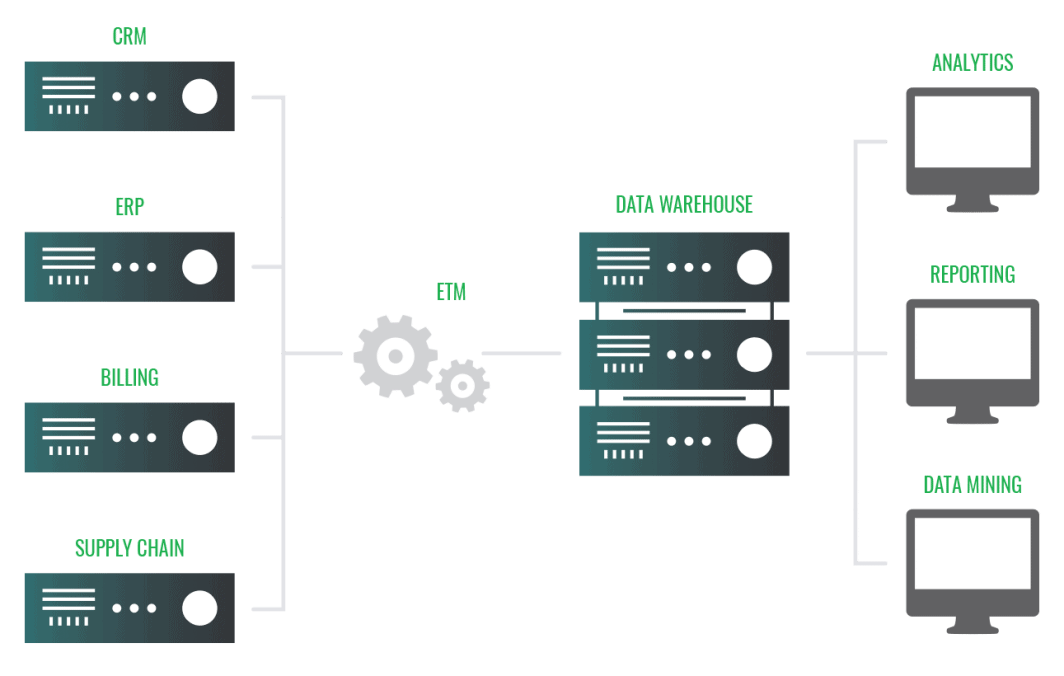
Data Warehousing: Store unstructured data in object storage for your data warehousing and data lake needs.
Understanding storage types and applying them appropriately across your organization should be a core component of your cloud strategy. Object storage provides massively scalable cloud storage and a common interface for a multi-cloud strategy. To learn a little bit more about common uses check out Cloud Object Storage Use Cases.



Comments